1. Variable Diffusion model (VDM)
1.1 Lịch sử hình thành
Những ý tưởng để hình thành nên mô hình diffussion model đã có từ rất lâu về trước nhưng đến tận năm 2021 chúng mới được phát triển mạnh mẽ .Trong bài viết này mình sẽ nói chung nguyên tắc cơ bản của diffussion_model .
Diffussion model được biết đến sớm nhất về ý tưởng này là dựa trên paper năm 2015 Deep Unsupervised Learning using Nonequilibrium Thermodynamics by Jascha Sohl-Dickstein et al. from Stanford University and UC Berkeley đã có từ 7 năm trước tức đã có từ rất rất lâu . Mọi ý tưởng chính bắt đầu từ nhiệt động lực học ( thermodynamics) , nếu bạn chưa biết nhiệt động lực học thì mình sẽ lấy một ví dụ đơn giản như sau:
Giả sử ta pha một tách cà phê với nước nóng quá trình trộn cà phê với nước đến khi cà phê hòa tan hoàn toàn đây được gọi là khuyếc tán thuận . Sau đó ta sẽ cố gắng tách cà phê ra khỏi nước nóng đây được gọi là khuyếc tán ngược . Tuy nhiên đây chỉ là câu nói mang tính chất giải trí vì hầu như ta không thể tách cà phê ra khỏi nước sau khi đã hòa tan hoàn toàn được nữa.
Mọi chuyện về ý tưởng khuyến tán vẫn tiếp tục sau 5 năm vắng bóng tất cả nguyên nhân là do sự áp đảo của GAN đã khiến mô hình khuyếc tán bị lu mờ trong những năm tháng qua đi . Mãi cho đến năm 2020by Jonathan Ho et al., also from UC Berkeley với tên gọi Denoising Diffusion Probabilistic Models (DDPM) tuy nhiên chúng chưa đủ mạnh mẽ để có thể thực sự đánh bại GAN . Sau một năm qua đi 2021 Improved Denoising Diffusion Probabilistic Models by OpenAI researchers Alex Nichol and Prafulla Dhariwal đã tạo nên một cú hích lớn để từ đó ta có các mô hình text2img nổi tiếng như bây giờ . Họ nhận thấy rằng diffussion model dễ đào tạo hơn GAN , hình ảnh đa dạng hơn và chất lượng ảnh cao hơn . Nhược điểm là chúng tồn rất nhiều thời gian để tạo ảnh do vấn đề T( Gaussian tiêu chuẩn ) số bước cần phải lớn như trong ví dụ trên đến khi cà phê thực sự hòa tan với nước.
1.2 Bắt đầu với khuyến tán thuận và khuyến tán ngược
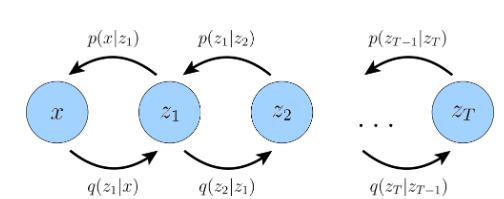
Tiếp túc từ series (1) chúng ta sẽ bắt đầu tìm hiểu thêm về quá trình khuyến tán dữ liệu .Như chúng ta đã biết về mô hình phân cấp VAE(Hierar-chical Variational Autoencode) thì chúng có ba điểm chính.
1 . Layer tiềm ẩn zz bằng với layer đầu vào xx hay như trên hình tức là số nút ẩn zz bằng số nút đầu vào xx
2 . Cấu trúc các layer tiềm ẩn zz ở mỗi bước TT không được học mà chỉ quanh quanh đầu ra trước đó tức là ví dụ z2{z_{2}} thì chúng chỉ hoạt đông dựa trên gaussion z3{z_{3}}
3 . Các tham số của layer zz sẽ thay đổi theo thời gian TT , TT là gaussian tiêu chuẩn
Miêu tả lại công thức quá trình decoder từ series 1:
p(x0,T)=p(xT)∏t=1Tpθ(xt−1∣xt)p ( x _ { 0 , T } ) = p ( x _ { T } ) prod _ { t = 1 } ^ { T } p _ { theta } ( x _ { t – 1 } | x _ { t } )
Hình 1:Mô tả quá trình hierarchical variational autoencoders
Hình 2: Mô tả quá trìn diffussion model
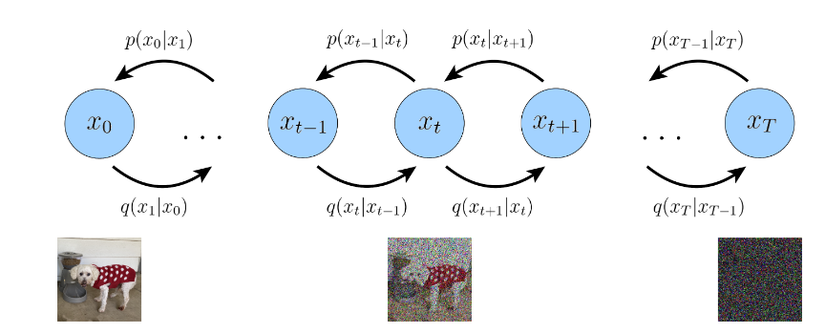
Dựa trên hình 2 ta sẽ xem xét điểm thứ nhất với một số điều chỉnh thay vì zz là layer tiềm ẩn ở đây ta sẽ thay đổi xtx_{t} là layer tiềm ẩn ở mội bước thời gian TT với t=0t=0 là ảnh input và t=[1,T]t= [1,T] là các layer tiềm ẩn , vì vậy ta có thể viết lại chúng thành.
1.2.1 Forward process (Khuyến tán thuận )
(1)
q(x1:T∣x0)=∏t=1Tq(xt∣xt−1)q ( x _ { 1 : T } | x _ { 0 } ) = prod _ { t = 1 } ^ { T } q ( x _ { t } | x _ { t – 1 } )
Tiếp theo xét điểm thứ hai diffussion model . Chúng là một gaussian tuyến tính với trung bình và phương sai đôi có thể được đặt như hyparameter . Ở diffussion model chúng tôi sẽ học tham số ở mỗi bước thời gian T luôn với giá trị trung bình .
Đặt αt=1−βt{alpha _ { t } = 1 – beta _ { t }} trong đó βt{beta _ { t }} với t=[1,T]t= [1,T] là một hyparameter sau đó được học thành parameter chính là lịch trình phương sai , nếu chúng hoạt động tốt chắc chắn xTx_{T} sẽ là một gaussian tiêu chuẩn với phương sai là 1 và trung bình là 0 .
Suy ra trung bình tổng thể:
(2)
μt(xt)=αtxt−1mu _ { t } ( x _ { t } ) = sqrt { alpha _ { t } } x _ { t – 1 }
Phương sai:
(3)
Σt(xt)=(1−αt)ISigma _ { t } ( x _ { t } ) = ( 1 – alpha _ { t } ) I
Quá trình encoder hay khuyến tán thuận ở mỗi layer tiềm ẩn luôn bảo toàn phương sai ( phương sai không hề thay đổi ở mỗi zt{z_{t}}) . Từ đó ta có thể nhận thấy rằng tỉ lệ noise ở mỗi bước t thời gian là như nhau và α{alpha} giống như β{beta} đều là một hyparameter sau đó đươc học thành parameter với các parameter thay đổi theo thời gian tt. Từ giờ ta sẽ sử dụng αt{alpha_{t}} thay vì βt{beta_{t}} , nhiều hướng dẫn hay bài báo để sử dụng β{beta} chúng vẫn là như nhau đều là lịch trình phương sai thay đổi theo thời gian tt.
Gói gọn từ phương trình (1) (2) (3) ta được
(4)
q(xt∣xt−1)=N(xt;αtxt−1,(1−αt)I)q ( x _ { t } | x _ { t – 1 } ) = N ( x _ { t } ; sqrt { alpha _ { t } } x _ { t – 1 } , ( 1 – alpha _ { t } ) I )
Tuy nhiên mặc dù ta đã biết đầu vào ảnh xt{x_{t}} với t=0t=0 là ảnh gốc tuy nhiên việc tính xt{x_{t}} với t=[1,T]t=[1,T] khi noise ảnh đầu vào chưa có thông tin . Điều này mình sẽ giải thích một chút .
Ta có thể tượng tượng từ hình ảnh 2 và phương trình 4 giả sử rằng x1{x_{1}} sẽ là ảnh đầu vào và x0{x_{0}} kết hợp với một gaussian với trung bình sẽ tạo ra ảnh x1{x_{1}} noise. Dựa trên câu nói trên ta biết được rằng.
(5)
xt∼N(xt−1,1)⇔xt=Xt−1+N(0,1)x _ { t } sim N ( x _ { t – 1 } , 1 ) Leftrightarrow x _ { t } = X _ { t – 1 } + N ( 0 , 1 )
ta biết rằng phân phối gaussian được viết là:
N(x;μ,σ)=1σ2πexp(−12(x−μσ)2)N ( x ; mu , sigma ) = frac { 1 } { sigma sqrt { 2 } pi } exp ( – frac { 1 } { 2 } ( frac { x – mu } { sigma } ) ^ { 2 } )
Chứng minh công thức (5) với tích phân luật xác suất toàn phần:

Nghĩa là nếu xt−1…{x_{t-1}… } sẽ tạo thành một không gian liên tục . Khi đó xtx_t sẽ là:
pXt(xt)=∫p(xt∣xt−1)p(xt−1)dxt−1p _ { X _ { t } } ( x _ { t } ) = int p ( x _ { t } | x _ { t – 1 } ) p ( x _ { t – 1 } ) d x _ { t – 1 }
Sau đó, chúng tôi thay thế phân phối có điều kiện bằng dạng Gaussian đã biết của nó
=∫N(xt;xt−1,1)p(xt−1)dxt−1= int N ( x _ { t } ; x _ { t – 1 } , 1 ) p ( x _ { t – 1 } ) d x _ { t – 1 }
Bây giờ chúng ta sẽ xắp xếp lại quy hoạch chúng như một phân phối gaussian chuẩn
=∫N(xt−xt−1;0,1)p(xt−1)dxt−1= int N ( x _ { t } – x _ { t – 1 } ; 0 , 1 ) p ( x _ { t – 1 } ) d x _ { t – 1 }
Áp dụng định nghĩa của tích chập ta được
=(N(0,1)∗pXt−1)(xt)= left ( N left ( 0 , 1 right ) * p _ { X _ { t – 1 } } right ) left ( x _ { t } right )
Ghép vào định luật xác xuất toàn phần ta được:
pXt(xt)=(N(0,1)∗pXt−1)(xt)p _ { X _ { t } } ( x _ { t } ) = ( N ( 0 , 1 ) * p _ { X _ { t – 1 } } ) ( x _ { t } )
Chia 2 vế đi Pxt{P_{x_{t}}} rút gọn:
(6)
Xt=X(0,1)+Xt−1X _ { t } = X ( 0 , 1 ) + X _ { t – 1 }
Từ (6) ta chứng minh được điều rằng là phân phối ở mỗi bước thời gian tt sẽ thông qua gausian trung bình và phân phối t−1t-1 thời gian trước đó như đã nói ở điểm thứ 2 .Tuy nhiên lưu ý một điều rằng là mình chưa sử dụng các tham số α{alpha} lịch trình phương sai . Vì đây chỉ là một lời giải thích ngắn gọn trước khi chúng ta kết hợp các trung bình và gaussian có α{alpha}. Đây chính là nguyên nhân tại sao có reparameter trick.Điều này cực kỳ quan trọng
1.2.2 Reverse process(Khuyến tán ngược)
Xét điểm thứ 3 Các tham số của layer zz sẽ thay đổi theo thời gian TT (TT là gaussian tiêu chuẩn) của HVAE nếu chuyển sang diffussion thì αt{alpha_{t}} cập nhật lịch trình phương sai và p(xT){p_(x_{T})} vẫn là một gaussian tiêu chuẩn và được viết lại theo toán học thành
(7)
p(x0:T)=p(xT)∏t=1Tpθ(xt−1∣xt)p ( x _ { 0 : T } ) = p ( x _ { T } ) prod _ { t = 1 } ^ { T } p _ { theta } ( x _ { t – 1 } | x _ { t } )
khi đó
p(xT)=N(xT;0,I)p ( x _ { T } ) = N ( x _ { T } ; 0 , I )
Lưu ý rằng các phân phối bộ encoder q(xt∣xt−1)q (x_{t} | x_{t-1}) của chúng tôi không còn được tham số hóa bởi ϕ{phi} nữa, vì chúng hoàn toàn được mô hình hóa dưới dạng Gaussian với các parameter trung bình và phương sai xác định tại mỗi bước thời gian. Do đó, trong một VDM, chúng ta chỉ quan tâm đến việc học các điều kiện pθ(xt−1∣xt){p_{theta} (x_{t-1} | x_{t})} , để chúng ta có thể mô phỏng dữ liệu mới. Sau khi tối ưu hóa VDM, quy trình lấy mẫu đơn giản như lấy mẫu nhiễu Gaussian từ p(xT){p(x_{T})} và chạy lặp đi lặp lại các bước chuyển đổi làm giảm pθ(xt−1∣xt){p_{theta} (x_{t-1} | x_{t})} cho T bước để tạo ra một x0{x_{0}} mới.
Giống như HVAE ta sẽ tối ưu hóa ELBO để cập nhật được các tham số θ{theta} tốt nhất , mọi quy tắc thức hiện giống y như series 1 đã viết.
(8)
logp(x)=log∫p(x0:T)dx1:Tlog p ( x ) = log int p ( x _ { 0 : T } ) d x _ { 1 : T }
(9)
=log∫p(x0:T)q(x1:T∣x0)q(x1:T∣x0)dx1:T= log int frac { p ( x _ { 0 : T } ) q ( x _ { 1 : T } | x _ { 0 } ) } { q ( x _ { 1 : T } | x _ { 0 } ) } d x _ { 1 : T }
Định nghĩa kỳ vọng (10)
=logEq(x1:T∣x0)[p(x0:T)q(x1:T∣x0)]= log E _ { q ( x _ { 1 : T } | x _ { 0 } ) } [ frac { p ( x _ { 0 : T } ) } { q ( x _ { 1 : T } | x _ { 0 } ) } ]
BDT jense (11)
≥Eq(x1:T∣x0)[logp(x0:T)q(x1:T∣x0)]geq operatorname { E } _ { q ( x _ { 1 : T } | x _ { 0 } ) } [ log frac { p ( x _ { 0 : T } ) } { q ( x _ { 1 : T } | x _ { 0 } ) } ]
Áp dụng phương trình số (1) và (7) ta được (12)
= Eq(x1:T∣x0)[logp(xT)∏t=1Tpθ(xt−1∣xt)∏t=1Tq(xt∣xt−1)]= E _ { q ( x _ { 1 : T } | x _ { 0 } ) } [ log frac { p ( x _ { T } ) prod _ { t = 1 } ^ { T } p _ { theta } ( x _ { t – 1 } | x _ { t } ) } { prod _ { t = 1 } ^ { T } q ( x _ { t } | x _ { t – 1 } ) }]
Tách tiếp (13)
= Eq(x1:T∣x0)[logp(xT)pθ(x0∣x1)∏t=2Tpθ(xt−1∣xt)q(xT∣xT−1)∏t=1T−1q(xt∣xt−1)]= E _ { q ( x _ { 1 : T } | x _ { 0 } ) } [ log frac { p ( x _ { T } ){p_{theta}(x_{0}|x_{1})} prod _ { t = 2 } ^ { T } p _ { theta } ( x _ { t – 1 } | x _ { t } ) } { q(x_{T}|x_{T-1})prod _ { t = 1 } ^ { T-1 } q ( x _ { t } | x _ { t – 1 } ) }]
Tách tiếp (14)
= Eq(x1:T∣x0)[logp(xT)pθ(x0∣x1)∏t=1T−1pθ(xt∣xt+1)q(xT∣xT−1)∏t=1T−1q(xt∣xt−1)]= E _ { q ( x _ { 1 : T } | x _ { 0 } ) } [ logfrac { p ( x _ { T } ) p _ { theta } ( x _ { 0 } | x _ { 1 } ) prod _ { t = 1 } ^ { T – 1 } p _ { theta } ( x _ { t } | x _ { t + 1 } ) } { q ( x _ { T } | x _ { T – 1 } ) prod _ { t = 1 } ^ { T – 1 } q ( x _ { t } | x _ { t – 1 } ) }]
(15)
= Eq(x1:T∣x0)[logp(xT)pθ(x0∣x1)q(xT∣xT−1)]+ Eq(x1:T∣x0)[log∏t=1T−1pθ(xt∣xt+1)q(xt∣xt−1)]= E _ { q ( x _ { 1 : T } | x _ { 0 } ) } [ logfrac { p ( x _ { T } ) p _ { theta } ( x _ { 0 } | x _ { 1 } ) } { q ( x _ { T } | x _ { T – 1 } ) }] + E _ { q ( x _ { 1 : T } | x _ { 0 } ) } [ logprod _ { t = 1 } ^ { T – 1 } frac { p _ { theta } ( x _ { t } | x _ { t + 1 } ) } { q ( x _ { t } | x _ { t – 1 } ) }]
(16)
=Eq(x1:T∣x0)[logpθ(x0∣x1)]+Eq(x1:T∣x0)[logp(xT)q(xT∣xT−1)]+Eq(x1:T∣x0)[∑t=1T−1logp0(xt∣xt+1)q(xt∣xt−1)]= E _ { q left ( x _ { 1 :T} | x _ { 0 } right ) } left [ log p _ { theta } left ( x _ { 0 } | x _ { 1 } right ) right ]+E _ { q ( x _ { 1 : T } | x _ { 0 } ) } [ log frac { p ( x _ { T } ) } { q ( x _ { T } | x _ { T – 1 } ) } ] + E _ { q ( x _ { 1 : T} | x _ { 0 } ) } [ sum _ { t = 1 } ^ { T – 1 } log frac { p _ { 0 } ( x _ { t } | x _ { t + 1 } ) } { q ( x _ { t } | x _ { t – 1 } ) } ]
(17)
=Eq(x1:T∣x0)[logpθ(x0∣x1)]+Eq(x1:T∣x0)[logp(xT)q(xT∣xT−1)]+∑t=1T−1Eq(x1:T∣x0)[logp0(xt∣xt+1)q(xt∣xt−1)]= E _ { q left ( x _ { 1 :T} | x _ { 0 } right ) } left [ log p _ { theta } left ( x _ { 0 } | x _ { 1 } right ) right ]+E _ { q ( x _ { 1 : T } | x _ { 0 } ) } [ log frac { p ( x _ { T } ) } { q ( x _ { T } | x _ { T – 1 } ) } ] + sum _ { t = 1 } ^ { T – 1 } E _ { q ( x _ { 1 : T} | x _ { 0 } ) } [ log frac { p _ { 0 } ( x _ { t } | x _ { t + 1 } ) } { q ( x _ { t } | x _ { t – 1 } ) } ]
(18)
=Eq(x1∣x0)[logpθ(x0∣x1)]+Eq(xT−1,xT∣x0)[logp(xT)q(xT∣xT−1)]+∑t=1T−1Eq(xt−1,xt,xt+1∣x0)[logpθ(xt∣xt+1)q(xt∣xt−1)]= E _ { q ( x _ { 1 } | x _ { 0 } ) } [ log p _ { theta } ( x _ { 0 } | x _ { 1 } ) ] + E _ { q ( x _ { T – 1 } , x _ { T } | x _ { 0 } ) } [ log frac { p ( x _ { T } ) } { q ( x _ { T } | x _ { T – 1 } ) } ] + sum _ { t = 1 } ^ { T – 1 } E _ { q left ( x _ { t – 1 } , x _ { t } , x _ { t + 1 } | x _ { 0 } right ) } left [ log frac { p _ { theta } left ( x _ { t } | x _ { t + 1 } right ) } { q left ( x _ { t } | x _ { t – 1 } right ) } right ]
Trong phương trình 18 có 3 đoạn tuy nhiên hãy để ý rằng Eq(x1:T∣x0){E_{q(x_{1:T}|x_{0})}} đã được thay đổi tùy theo các đoạn khác nhau sẽ có một chút thác mắc với bạn đọc , vậy nên tôi sẽ giải theo ý hiểu của bản thân rằng là. Giả sử đoạn 1.
Eq(x1∣x0)[logpθ(x0∣x1)]E _ { q ( x _ { 1 } | x _ { 0 } ) } [ log p _ { theta } ( x _ { 0 } | x _ { 1 } ) ]
Do ta nhận thấy rằng pθ(x0∣x1){p_{theta}(x_{0}|x_{1})} không tồn tại trong encoder khuyến tán thuận q(x0∣x1){q(x_{0}|x_{1})} tuy nhiên để ý rằng trong hình 2 q(x1∣x0){q(x_{1}|x_{0})} và p(x0∣x1){p(x_{0}|x_{1})} chắc chắn rằng chúng phải thỏa mãn với điều kiện bằng nhau(tương đương với nhau) nên ở đây mới có q(x0∣x1){q(x_{0}|x_{1})}. Hơn nữa x0{x_{0}} là giá trị ảnh đầu vào tức luôn luôn có điều kiện x0{x_{0}} mọi yếu tố của các bước thời gian tt khi khuyến tán thuận luôn có điều kiện quan trọng ảnh đầu vào , x0{x_{0}} luôn luôn liên kết liên tiếp với các ảnh noise theo thời gian t.Tương tự với các đoạn còn lai cũng giải thích như vậy.
1.3 Loss Function
(19) Từ phương trình (18)
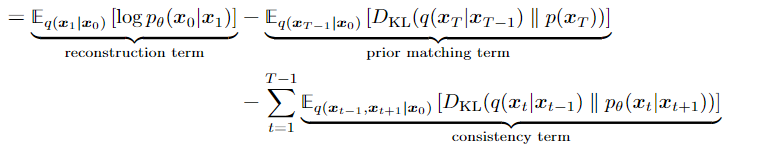
Ta sẽ giải thích 3 đoạn của phương trình (19) như sau:
- Đoạn 1: reconstruction term :dự đoán log xác suất của ảnh dựa trên ảnh noise đầu tiên
- Đoạn 2 : prior matching term : Mặc định bằng 0 do không có parameter khoảng cách phân phối khuyến tán thuận qT{q_{T}} cuối cùng và khuyến tán ngược pT{p_{T}} đầu tiên và do cả hai chắc chắn là một gaussian tiêu chuẩn nên chắc chắn là bằng 0
- Đoạn 3: consistency term : Khoảng cách giữa các layer tiềm ẩn khi khuyến tán thuận và các layer tiềm ẩn khi khuyến tán ngược chúng phải cố gắng tối ưu hóa sao cho chúng bằng nhau tức nhỏ nhất 0. Mình sẽ cố gắng giải thích bằng hình minh họa sau:
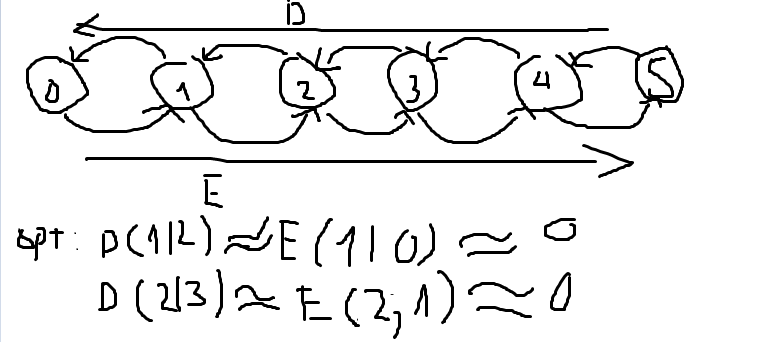
Tôi ưu hóa : Optimizers và sử dụng xấp xỉ để ấm chỉ hai thứ đó gần bằng nhau và đều bằng 0 đó chính xác là mục tiêu mà chúng ta muốn tối ưu hóa và trên hết decoder khuyến tán ngược có tham số theta sẽ cập nhật
Sau đây mình sẽ chia sẻ nốt về KL dùng để đo khoảng cách giữa hai phân phối.
DKL(P∣∣Q)=∫−∞∞p(x)log(p(x)q(x))dxD _ { K L } ( P | | Q ) = int _ { – infty } ^ { infty } p ( x ) log ( frac { p ( x ) } { q ( x ) } ) d x
Dưới đây, bạn có thể thấy sự phân kỳ KL của một phân phối thay đổi P (xanh lam) từ một phân phối tham chiếu Q (đỏ). Đường cong màu xanh lá cây biểu thị hàm trong tích phân trong định nghĩa cho phân kỳ KL ở trên và tổng diện tích dưới đường cong biểu thị giá trị của phân kỳ KL của P từ Q tại bất kỳ thời điểm nào, một giá trị cũng được hiển thị bằng số.
Mặc dù phương trình số (18) đã đem lại cho chúng ta một hàm tối ưu hóa ELBO nhưng thực sự có phải vậy chăng , đó có chinh xác là một thuật ngữ tối ưu hóa cho ELBO . Không hãy để ý đoạn 3 của phương trình 18 có 2 biến ngẫu nhiên {xt−1{x_{t-1}} và xt+1{x_{t+1}}} mà ước tính Monte Carlo chỉ có khả năng dự đoán tốt với duy nhất 1 biến ngẫu nhiên , đối với T lớn ELBO
∑t=1T−1Eq(xt−1,xt,xt+1∣x0)[logpθ(xt∣xt+1)q(xt∣xt−1)]sum _ { t = 1 } ^ { T – 1 } E _ { q left ( x _ { t – 1 } , x _ { t } , x _ { t + 1 } | x _ { 0 } right ) } left [ log frac { p _ { theta } left ( x _ { t } | x _ { t + 1 } right ) } { q left ( x _ { t } | x _ { t – 1 } right ) } right]
có khả năng mang lại phương sai cao tức là ovefting . Vậy nên ở đây ta tạo ra một hình vẽ minh họa cho diffussion model tiếp theo để chỉnh sửa chút về ELBO. Tìm hiểu thêm về Monte carlo tham khảo
Hình 3:
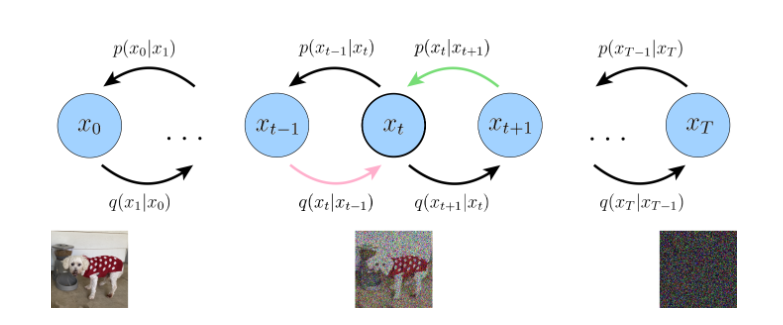
Mục tiêu lần này của chúng ta sẽ cố gắng để cho consistency term kỳ vọng duy nhất vào một biến ngẫu nhiên đây sẽ là mục tiêu của chúng tôi. Ở đây ta áp dụng đinh lý bayess để viết lại encoder khuyến tán thuận như sau , lưu ý :
(20)
q(xt∣xt−1,x0)=q(xt∣xt−1)=N(xt;αtxt−1,(1−αt)I)q ( x _ { t } | x _ { t – 1 } , x _ { 0 } ) = q ( x _ { t } | x _ { t – 1 }) = N ( x _ { t } ; sqrt { alpha _ { t } } x _ { t – 1 } , ( 1 – alpha _ { t } ) I )
Định lý bayess 21
q(xt∣xt−1,x0)=q(xt−1∣xt,x0)q(xt∣x0)q(xt−1∣x0)q ( x _ { t } | x _ { t – 1 } , x _ { 0 } ) = frac { q ( x _ { t – 1 } | x _ { t } , x _ { 0 } ) q ( x _ { t } | x _ { 0 } ) } { q ( x _ { t – 1 } | x _ { 0 } ) }
Áp dụng phương trình (11)
(22)
logp(x)≥Eq(x1:T∣x0)[logp(x0:T)q(x1,T∣x0)]log p ( x ) geq E _ { q ( x _ { 1 : T } | x _ { 0 } ) } [ log frac { p ( x _ { 0 : T} ) } { q ( x _ { 1 , T } | x _ { 0 } ) } ]
(23) Dựa trên phương trình (1) và (7)
=Eq(x1:T∣x0)[logp(xT)∏t=1Tpθ(xt−1∣xt)∏t=1Tq(xt∣xt−1)]= E _ { q ( x _ { 1 } : _ { T } | x _ { 0 } ) } [ log frac { p ( x _ { T } ) prod _ { t = 1 } ^ { T } p _ { theta } ( x _ { t – 1 } | x _ { t } ) } { prod _ { t =1} ^ { T } q ( x _ { t } | x _ { t – 1 } ) } ]
(24)
=Eq(x1:T∣x0)[logp(xT)p0(x0∣x1)∏t=2Tp0(xt−1∣xt)q(x1∣x0)∏t=2Tq(xt∣xt−1)]= E _ { q ( x _ { 1 :T} | x _ { 0 } ) } [ log frac { p ( x _ { T } ) p _ { 0 } ( x _ { 0 } | x _ { 1 } ) prod _ { t = 2 } ^ { T } p _ { 0 } ( x _ { t – 1 } | x _ { t } ) } { q ( x _ { 1 } | x _ { 0 } ) prod _ { t = 2 } ^ { T } q ( x _ { t } | x _ { t – 1 } ) } ]
(25) Dựa trên phương trình (20)
=Eq(x1:T∣x0)[logp(xT)p0(x0∣x1)∏t=2Tp0(xt−1∣xt)q(x1∣x0)∏t=2Tq(xt∣xt−1,x0)]= E _ { q ( x _ { 1 :T} | x _ { 0 } ) } [ log frac { p ( x _ { T } ) p _ { 0 } ( x _ { 0 } | x _ { 1 } ) prod _ { t = 2 } ^ { T } p _ { 0 } ( x _ { t – 1 } | x _ { t } ) } { q ( x _ { 1 } | x _ { 0 } ) prod _ { t = 2 } ^ { T } q ( x _ { t } | x _ { t – 1 },x_{0} ) } ]
(26) bảng log(a.b) = log(a)+ log(b)
=Eq(x1:T∣x0)[logpθ(xT)pθ(x0∣x1)q(x1∣x0)+log∏t=2Tpθ(xt−1∣xt)q(xt∣xt−1,x0)]= E _ { q ( x _ { 1 :T } | x _ { 0 } ) } [ log frac { p _ { theta } ( x _ { T } ) p _ { theta } ( x _ { 0 } | x _ { 1 } ) } { q ( x _ { 1 } | x _ { 0 } ) } + log prod _ { t = 2 } ^ { T } frac { p _ { theta } ( x _ { t – 1 } | x _ { t } ) } { q ( x _ { t } | x _ { t – 1 } , x _ { 0 } ) } ]
(27) Dựa trên phương trình (21)
=Eq(x1:T∣x0)[logpθ(xT)pθ(x0∣x1)q(x1∣x0)+log∏t=2Tpθ(xt−1∣xt)q(xt−1∣xt,x0)q(xt∣x0)q(xt−1∣x0)]= E _ { q ( x _ { 1 :T } | x _ { 0 } ) } [ log frac { p _ { theta } ( x _ { T } ) p _ { theta } ( x _ { 0 } | x _ { 1 } ) } { q ( x _ { 1 } | x _ { 0 } ) } + log prod _ { t = 2 } ^ { T } frac { p _ { theta } ( x _ { t – 1 } | x _ { t } ) } {frac { q ( x _ { t – 1 } | x _ { t } , x _ { 0 } ) q ( x _ { t } | x _ { 0 } ) } { q ( x _ { t – 1 } | x _ { 0 } ) }}]
(28)
=Eq(x1:T∣x0)[logpθ(xT)pθ(x0∣x1)q(x1∣x0)+log∏t=2Tpθ(xt−1∣xt)q(xt−1∣x0)q(xt−1∣xt,x0)q(xt∣x0)]= E _ { q ( x _ { 1 :T } | x _ { 0 } ) } [ log frac { p _ { theta } ( x _ { T } ) p _ { theta } ( x _ { 0 } | x _ { 1 } ) } { q ( x _ { 1 } | x _ { 0 } ) } + log prod _ { t = 2 } ^ { T } frac { p _ { theta } ( x _ { t – 1 } | x _ { t } ) { q ( x _ { t – 1 } | x _ { 0 } ) }} { q ( x _ { t – 1 } | x _ { t } , x _ { 0 } ) q ( x _ { t } | x _ { 0 } ) }]
mà ta có :
∏t=2Tq(xt−1∣x0)=q(x1∣x0)q(x2∣x0)q(x3∣x0)q(x4∣x0)q(x5∣x0)…..q(xT−1∣x0)prod_ { t = 2 } ^ { T } { q ( x _ { t – 1 } | x _ { 0 } ) }= q(x_{1}|x _ { 0 })q(x_{2}|x _ { 0 })q(x_{3}|x _ { 0 })q(x_{4}|x _ { 0 })q(x_{5}|x _ { 0 })…..q(x_{T-1}|x _ { 0 })
∏t=2Tq(xt∣x0)=q(x2∣x0)q(x3∣x0)q(x4∣x0)q(x5∣x0)…..q(xT∣x0)prod_ { t = 2 } ^ { T } { q ( x _ { t } | x _ { 0 } ) }= q(x_{2}|x _ { 0 })q(x_{3}|x _ { 0 })q(x_{4}|x _ { 0 })q(x_{5}|x _ { 0 })…..q(x_{T}|x _ { 0 })
Từ hai phương trình trên ta có thể khẳng định rằng là:
∏t=2Tq(xt−1∣x0)q(xt∣x0)=q(x1∣x0)q(x2∣x0)q(x3∣x0)q(x4∣x0)q(x5∣x0)…..q(xT−1∣x0)q(x2∣x0)q(x3∣x0)q(x4∣x0)q(x5∣x0)…..q(xT−1∣x0)q(xT∣x0)prod_ { t = 2 } ^ { T } frac{ q ( x _ { t – 1 } | x _ { 0 } ) } { q ( x _ { t } | x _ { 0 } ) } = frac {q(x_{1}|x _ { 0 })q(x_{2}|x _ { 0 })q(x_{3}|x _ { 0 })q(x_{4}|x _ { 0 })q(x_{5}|x _ { 0 })…..q(x_{T-1}|x _ { 0 })}{q(x_{2}|x _ { 0 })q(x_{3}|x _ { 0 })q(x_{4}|x _ { 0 })q(x_{5}|x _ { 0 })…..q(x_{T-1}|x _ { 0 })q(x_{T}|x _ { 0 })}
∏t=2Tq(xt−1∣x0)q(xt∣x0)=q(x1∣x0)q(xT∣x0)prod_ { t = 2 } ^ { T } frac{ q ( x _ { t – 1 } | x _ { 0 } ) } { q ( x _ { t } | x _ { 0 } ) } =frac {q(x_{1}|x _ { 0 })}{q(x_{T}|x _ { 0 })}
(29)
=Eq(x1:T∣x0)[logp(xT)pθ(x0∣x1)q(x1∣x0)+logq(x1∣x0)q(xT∣x0)+log∏t=2Tpθ(xt−1∣xt)q(xt−1∣xt,x0)]= E _ { q ( x _ { 1 : T } | x _ { 0 } ) }[log frac { p ( x _ { T } ) p _ { theta } ( x _ { 0 } | x _ { 1 } ) } { q ( x _ { 1} | x _ { 0 } ) } + log frac { q ( x _ { 1 } | x _ { 0 } ) } { q ( x _ { T } | x _ { 0 } ) }+ log prod _ { t = 2 } ^ { T } frac { p _ { theta } ( x _ { t – 1 } | x _ { t } ) } { q ( x _ { t – 1 } | x _ { t } , x _ { 0 } ) }]
(30) chia 2 vế đầu cho q(x1∣x0){q_(x{1}|x{0})} ta được:
=Eq(x1:T∣x0)[logp(xT)pθ(x0∣x1)q(xT∣x0)+∑t=2Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)]= E _ { q ( x _ { 1 : T } | x _ { 0 } ) } [ log frac { p ( x _ { T } ) p _ { theta } ( x _ { 0 } | x _ { 1 } ) } { q ( x _ { T } | x _ { 0 } ) } + sum _ { t = 2 } ^ { T } log frac { p _ { theta } ( x _ { t – 1 } | x _ { t } ) } { q ( x _ { t – 1 } | x _ { t } , x _ { 0 } ) } ]
(31)
=Eq(x1:T∣x0)[logpθ(x0∣x1)]+Eq(x1:T∣x0)[logp(xT)q(xT∣x0)]+∑t=2TEq(x1:T∣x0)[logpθ(xt−1∣xt)q(xt−1∣xt,x0)]= E _ { q left ( x _ { 1 :T } | x _ { 0 } right ) } left [ log p _ { theta } left ( x _ { 0 } | x _ { 1 } right ) right ] + E _ { q ( x _ { 1 : T } | x _ { 0 } ) } [ log frac { p ( x _ { T } ) } { q ( x _ { T } | x _ { 0 } ) } ]+
sum _ { t = 2 } ^ { T } E _ { q ( x _ { 1 :T } | x _ { 0 } ) } [ log frac { p _ { theta } ( x _ { t – 1 } | x _ { t } ) } { q ( x _ { t – 1 } | x _ { t } , x _ { 0 } ) } ]
(32)
=Eq(x1∣x0)[logpθ(x0∣x1)]+Eq(xT∣x0)[logp(xT)q(xT∣x0)]+∑t=2TEq(xt,xt−1∣x0)[logpθ(xt−1∣xt)q(xt−1∣xt,x0)]= E _ { q left ( x _ { 1 } | x _ { 0 } right ) } left [ log p _ { theta } left ( x _ { 0 } | x _ { 1 } right ) right ] + E _ { q ( x _ { T } | x _ { 0 } ) } [ log frac { p ( x _ { T } ) } { q ( x _ { T } | x _ { 0 } ) } ]+
sum _ { t = 2 } ^ { T } E _ { q ( x _ { t },x_{t-1} | x _ { 0 } ) } [ log frac { p _ { theta } ( x _ { t – 1 } | x _ { t } ) } { q ( x _ { t – 1 } | x _ { t } , x _ { 0 } ) } ]
(33)
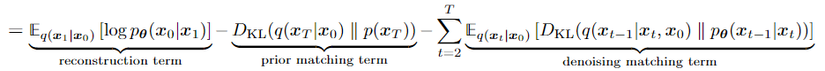
Ở đây chúng tôi đã viết ại ELBO một cách khiến có phương sai thấp hơn , hơn nữa chúng ta đã làm được một điều đó là khiến các kỳ vọng ở mỗi đoạn có đúng một biến ngẫu nhiên. Đây chính là Loss function của diffussion mà chúng ta cần tìm
Ta sẽ tiếp tục giải thích phương trình (33) như sau:
- Đoạn 1 : reconstruction term (tái tạo ) dự đoán log xác suất của ảnh dựa trên ảnh noise đầu tiên tối ưu hóa bằng cách sử dụng ước tính Monte Carlo
argmaxθEq(x1∣x0)[logpθ(x0∣x1)]−DKL(q(xT∣x0)∥p(xT))underset { theta } { arg max } E_{ q left ( x _ { 1 } | x _ { 0 } right ) } [ log p _ { theta } ( x_{0} | x_{1} ) ] – D _ { K L } ( q _ { } ( x_{T} | x_{0} ) | p ( x_{T} ) )
- Đoạn 2: prior matching term : Mặc định bằng 0 do không có parameter khoảng cách phân phối khuyến tán thuận qT{q_{T}} cuối cùng và khuyến tán ngược pT{p_{T}} đầu tiên và do cả hai chắc chắn là một gaussian tiêu chuẩn nên chắc chắn là bằng 0
- Đoạn 3: denoising matching term:Khoảng cách giữa các layer tiềm ẩn khi khuyến tán thuận và các layer tiềm ẩn khi khuyến tán ngược chúng phải cố gắng tối ưu hóa sao cho chúng bằng nhau tức nhỏ nhất 0. Nhìn vào hình 5 ta biết được rằng đường màu hồng và đường màu xanh q(xt−1∣xt,x0=p(xt−1∣xt){q(x_{t-1}|x_{t},x_{0} = p(x_{t-1}|x_{t})} (điều kiện tối ưu hóa mong muốn) hay q(xt∣xt+1,x0=p(xt∣xt+1){q(x_{t}|x_{t+1},x_{0} = p(x_{t}|x_{t+1})}
Hình 5:
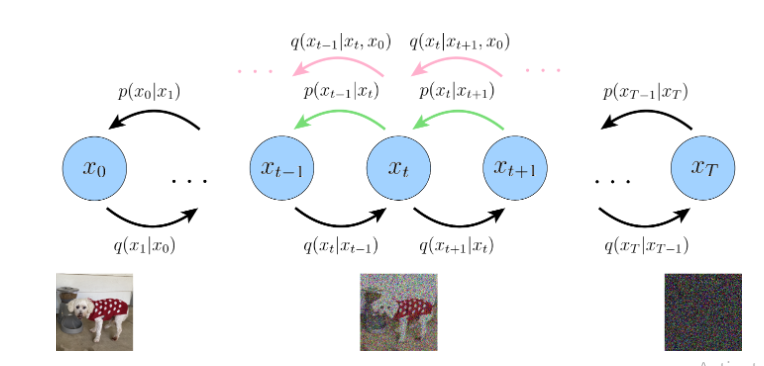
Trong phương trình (33) phần lớn khả năng tính toán dựa vào reconstruction term trong khi denoising matching term rất khó để học chúng do sự phức tạp giữa chúng khi phải tính tham số decoder p(xt−1∣xt){p(x_{t-1}|x_{t})} và cả bộ encoder mặc dù encoder không có parameter . Vậy nên ta sẽ tiếp tục đào sâu về gaussian chuyển tiếp để tối ưu hóa chúng , áp dụng đinh lý bayess:
(35)
q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt−1∣x0)q(xt∣x0)q ( x _ { t – 1 } | x _ { t } , x _ { 0 } ) = frac { q ( x _ { t } | x _ { t – 1 } , x _ { 0 } ) q ( x _ { t – 1 } | x _ { 0 } ) } { q ( x _ { t } | x _ { 0 } ) }
Như ta đã biết áp dụng phương trình (4) và (20) ta được
q(xt∣xt−1,x0)=q(xt∣xt−1)=N(xt;αtxt−1,(1−αt)I)q ( x _ { t } | x _ { t – 1 } , x _ { 0 } ) = q ( x _ { t } | x _ { t – 1 } ) = N ( x _ { t } ; sqrt { alpha _ { t } } x _ { t – 1 } , ( 1 – alpha _ { t } ) I )
Từ kết luận từ phương trình số (6) ta biết được tại sao có reparameter trick:
xt∼q(xt∣xt−1)x _ { t } sim q ( x _ { t } | x _ { t – 1 } )
có thể viết lại thành (36)
xt=αtxt−1+1−αtϵ with ϵ∼N(ϵ;0,I)x _ { t } = sqrt { alpha _ { t } } x _ { t – 1 } + sqrt { 1 – alpha _ { t } } epsilon quad text { with } epsilon sim N ( epsilon ; 0 , I )
Rất giống với phương trình số (6) duy nhất có sự thay đổi ở đây là các parameter alpha lịch trình học tập tương ứng với trung bình mẫu và phương sai
Tương tự như vậy thì:
xt−1∼q(xt−1∣xt−2)x _ { t -1} sim q ( x _ { t -1} | x _ { t -2 } )
có thể viết lượng thành (37)
xt−1=αt−1xt−2+1−αt−1ϵ with ϵ∼N(ϵ;0,I)x _ { t-1 } = sqrt { alpha _ { t-1 } } x _ { t – 2 } + sqrt { 1 – alpha _ { t -1} } epsilon quad text { with } epsilon sim N ( epsilon ; 0 , I )
Hình 5 miêu tả một cách phương sai thấp hơn để tối ưu hóa Diffussion model , tính toán các layer tiềm ẩn khuyến tán thuận q(xt−1∣xt,x0){q (x_{t-1} | x_{t}, x_{0})} bằng cách sử dụng quy tắc Bayes và giảm thiểu Phân kỳ KL của nó sao cho gần đúng pθ(xt−1∣xt){p_{theta}(x_{t-1} | x_{t})}. Hiển thị bằng các mũi tên màu xanh lá cây với các phân bố của các mũi tên màu hồng.,mỗi mũi tên màu hồng cũng phải xuất phát từ x0{x_{0}}, vì nó cũng là một thuật ngữ denoising matching term.
Khi đó q(xt−1∣xt,x0){q (x_{t-1} | x_{t}, x_{0})} với
{ϵt∗,ϵt}t=0T∼N(ϵ;0,I){ epsilon _ { t } ^ { * } , epsilon _ { t } } _ { t = 0 } ^ { T } stackrel { } { sim } N ( epsilon ; 0 , I )
Ta sẽ tính mọi ảnh noise theo thời gian t dựa trên đầu vào ảnh, điều này cực kỳ quan trọng vì nó chính là mọi quy tắc của ảnh noise tiếp theo của khuyến tán thuận. Ta sẽ ký hiệu chúng là:
(*)
xt∼q(xt∣x0)x _ { t} sim q ( x _ { t } | x _ { 0 } )
và xt{x_{t}} với t=[1,T]t = [1,T ] được viết lại thành:
(38)
xt=αtxt−1+1−αtϵt−1∗x _ { t } = sqrt { alpha _ { t } } x _ { t – 1 } + sqrt { 1 – alpha _ { t } } epsilon _ { t – 1 } ^ { * }
(39) thay (37) vào (38)
=αt(αt−1xt−2+1−αt−1ϵt−2∗)+1−αtϵt−1∗= sqrt { alpha _ { t } } ( sqrt { alpha _ { t – 1 } } x _ { t – 2 } + sqrt { 1 – alpha _ { t – 1 } } epsilon _ { t – 2 } ^ { * } ) + sqrt { 1 – alpha _ { t } } epsilon _ { t – 1 } ^ { * }
(40) quy tắc nhân căn bậc 2 với 2 số không âm
=αtαt−1xt−2+αt1−αt−1−ϵt−2∗+1−αtϵt−1∗= sqrt { alpha _ { t } } sqrt { alpha _ { t – 1 } } x _ { t – 2 } + sqrt { alpha _ { t } }sqrt { 1 – alpha _ { t – 1 } } – epsilon _ { t – 2 } ^ { * } + sqrt { 1 – alpha _ { t } } epsilon _ { t – 1 } ^ { * }
(41)
=αtαt−1xt−2+1αt−αtαt−1ϵt−2∗+1−αtϵt−1∗= sqrt { alpha _ { t } alpha _ { t – 1 } } x _ { t – 2 } + sqrt { 1alpha _ { t } – alpha _ { t } alpha _ { t – 1 } } epsilon _ { t – 2 } ^ { * } + sqrt { 1 – alpha _ { t } } epsilon _ { t – 1 } ^ { * }
Bình phương 2 vế bên phải trong căn để dễ dàng tính Tổng các biến ngẫu nhiên có trong phân phối
(42)
=αtαt−1xt−2+αt−αtαt−12ϵt−2∗+1−αt2ϵt−1∗= sqrt { alpha _ { t } alpha _ { t – 1 } } x _ { t – 2 } + sqrt { sqrt { alpha _ { t } – alpha _ { t } alpha _ { t – 1 } } ^ { 2 }epsilon _ { t – 2 }^{*} + sqrt { 1 – alpha _ { t } }^{2} epsilon _ { t – 1 }^{*}}
Nên nhớ rằng đây là phân phối gaussian chuẩn nên trung bình mẫu là 0. Hãy xét vé bên phải căn bình phương đầu tiên sẽ được viết thành như này:
(43)
αt−αtαt−12ϵt−2∗∼N(0,(αt−αtαt−1)I)sqrt { alpha _ { t } – alpha _ { t } alpha _ { t – 1 } } ^ { 2 }epsilon _ { t – 2 }^{*} sim N ( 0 , ( alpha _ { t } – alpha _ { t } alpha _ { t – 1 } ) I )
Vế bên phải căn bình phương cuối cùng như sau:
(44)
1−αt2ϵt−1∗∼N˙(0,(1−αt)I)sqrt { 1 – alpha _ { t } }^{2} epsilon _ { t – 1 }^{*}sim dot { N } ( 0 , ( 1 – alpha _ { t } ) I )
(45) Tổng các biến ngẫu nhiên có trong phân phối (43) và (44)
N(0,(1−αt+αt−αtαt−1)I)=N(0,(1−αtαt−1)I)N ( 0 , ( 1 – alpha _ { t } + alpha _ { t } – alpha _ { t } alpha _ { t – 1 } ) I ) = N ( 0 , ( 1 – alpha _ { t } alpha _ { t – 1 } ) I )
Từ (45) ta có (46)
=αtαt−1xt−2+αt−αtαt−1+1−αtϵt−1∗ϵt−2∗= sqrt { alpha _ { t } alpha _ { t – 1 } } x _ { t – 2 } + sqrt { alpha _ { t } – alpha _ { t } alpha _ { t – 1 } + 1 – alpha _ { t } } epsilon _ { t – 1 }^{*}epsilon _ { t – 2 }^{*}
(47)
=αtαt−1xt−2+1−αtαt−1ϵt−1∗ϵt−2∗= sqrt { alpha _ { t } alpha _ { t – 1 } } x _ { t – 2 } + sqrt { 1 – alpha _ { t } alpha _ { t – 1 } } epsilon _ { t – 1 }^{*}epsilon _ { t – 2 }^{*}
(48) Ở đây ta sẽ tiếp tục viết tương tự như vậy:
xt−2=αt−2xt−3+1−αt−2ϵ with ϵ∼N(ϵ;0,I)x _ { t-2 } = sqrt { alpha _ { t-2 } } x _ { t – 3 } + sqrt { 1 – alpha _ { t -2} } epsilon quad text { with } epsilon sim N ( epsilon ; 0 , I )
(49) Từ (48) ta thay tiếp vào (47):
=αtαt−1(αt−2xt−3+1−αt−2ϵt−3∗)+1−αtαt−1ϵt−1∗ϵt−2∗= sqrt { alpha _ { t } alpha _ { t – 1 } } (sqrt { alpha _ { t-2 } } x _ { t – 3 } + sqrt { 1 – alpha _ { t -2} } epsilon_ { t – 3 }^{*}) +sqrt { 1 – alpha _ { t } alpha _ { t – 1 } } epsilon _ { t – 1 }^{*}epsilon _ { t – 2 }^{*}
(50)
=αtαt−1αt−2xt−3+αtαt−1−αtαt−1αt−2ϵt−3∗+1−αtαt−1ϵt−1∗ϵt−2∗= sqrt { alpha _ { t } alpha _ { t – 1 }alpha _ { t-2 } }x _ { t – 3 } + sqrt{alpha _ { t } alpha _ { t – 1 } – alpha _ { t } alpha _ { t – 1 }alpha _ { t-2 }}epsilon_ { t – 3 }^{*}
+sqrt { 1 – alpha _ { t } alpha _ { t – 1 } } epsilon _ { t – 1 }^{*}epsilon _ { t – 2 }^{*}
(51)
=αtαt−1αt−2xt−3+αtαt−1−αtαt−1αt−22+1−αtαt−12ϵt−1∗ϵt−2∗ϵt−3∗= sqrt { alpha _ { t } alpha _ { t – 1 }alpha _ { t-2 } }x _ { t – 3 } + sqrt{sqrt{alpha _ { t } alpha _ { t – 1 } – alpha _ { t } alpha _ { t – 1 }alpha _ { t-2 }}^{2}
+sqrt { 1 – alpha _ { t } alpha _ { t – 1 } }^{2}} epsilon _ { t – 1 }^{*}epsilon _ { t – 2 }^{*}epsilon_ { t – 3 }^{*}
(52)
=αtαt−1αt−2xt−3+1−αtαt−1αt−2ϵt−3= sqrt { alpha _ { t } alpha _ { t – 1 }alpha _ { t-2 } }x _ { t – 3 } + sqrt{1-alpha_{t}alpha _ { t – 1 }alpha _ { t-2 }} epsilon_ { t – 3 }
=……………………………………………………………………..= ……………………………………………………………………..
Do mọi ϵ{epsilon} đều có phân phối chuản nên khi nhân với nhau chúng vẫn giữ nguyên mặc định nên ở đây tôi gói gọn trong ϵt−3{epsilon_{t-3}}
(53) rút gọn về thành:
=∏i=1tαix0+1−∏i=1tαiϵ0= sqrt { prod _ { i = 1 } ^ { t } alpha _ { i } x _ { 0 } + } sqrt { 1 – prod _ { i = 1 } ^ { t } alpha _ { i } epsilon _ { 0 } }
(54)
=α‾tx0+1−α‾tϵ0= sqrt { overline { alpha } _ { t } } x _ { 0 } + sqrt { 1 – overline { alpha } _ { t } } epsilon _ { 0 }
(55)
∼N(xt;α‾tx0,(1−α‾t)I)sim N ( x _ { t } ; sqrt { overline { alpha } _ { t } } x _ { 0 } , ( 1 – overline { alpha } _ { t } ) I )
Đây chính là reparameterization trick của Diffussion model
Do đó, chúng tôi suy ra Gaussian của q(xt∣x0){q (x_{t} | x_{0})}. Đạo hàm của chúng có thể biến thành parameterization Gaussian q(xt−1∣x0){q (x_{t − 1} | x_{0})}. Bây giờ, khi biết q(xt∣x0){q (x_{t} | x_{0})} và q(xt−1∣x0){q (x_{t − 1} | x_{0})} từ (*) chúng ta có thể tiến hành tính dạng của q(xt−1∣xt,x0){q (x_{t − 1} | x_{t}, x_{0})} bằng cách thay thế vào khai triển quy tắc Bayes:
(56)
q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt−1∣x0)q(xt∣x0)q ( x _ { t – 1 } | x _ { t } , x _ { 0 } ) = frac { q ( x _ { t } | x _ { t – 1 } , x _ { 0 } ) q ( x _ { t – 1 } | x _ { 0 } ) } { q ( x _ { t } | x _ { 0 } ) }
Từ (*) và (55) ta biết :
q(xt∣x0)∼N(xt;α‾tx0,(1−α‾t)I){ q ( x _ { t } | x _ { 0 } ) } sim N ( x _ { t } ; sqrt { overline { alpha } _ { t } } x _ { 0 } , ( 1 – overline { alpha } _ { t } ) I )
Từ đó:
q(xt−1∣x0)∼N(xt−1;α‾t−1×0,(1−α‾t−1)I){ q ( x _ { t -1 } | x _ { 0 } ) } sim N ( x _ { t -1 } ; sqrt { overline { alpha } _ { t -1 } } x _ { 0 } , ( 1 – overline { alpha } _ { t -1 } ) I )
(57) Dựa trên (20)
=N(xt;αtxt−1,(1−αt)I)N(xt−1;α‾t−1×0,(1−α‾t−1)I)N(xt:α‾tx0,(1−α‾t)I)= frac { N ( x _ { t } ; sqrt { alpha _ { t } } x _ { t – 1 } , ( 1 – alpha _ { t } ) I ) N ( x _ { t – 1 } ; sqrt { overlinealpha _ { t – 1 } } x _ { 0 } , ( 1 – overline { alpha } _ { t – 1 } ) I ) } { N ( x _ { t : } sqrt { overline { alpha } _ { t } } x _ { 0 } , ( 1 – overline { alpha } _ { t } ) I ) }
(58)
Áp dụng công thức logarit tự nhiên và gaussian:
∝exp{−[(xt−αtxt−1)22(1−αt)+(xt−1−α‾t−1×0)22(1−α‾t−1)−(xt−α‾tx0)22(1−α‾t)]}propto exp { – [frac { ( x _ { t } – sqrt { alpha _ { t } } x _ { t – 1 } ) ^ { 2 } } { 2 ( 1 – alpha _ { t } ) }+ frac { ( x _ { t – 1 } – sqrt { overline { alpha } _ { t – 1 } } x _ { 0 } ) ^ { 2 } } { 2 ( 1 – overline { alpha } _ { t – 1 } ) } – frac { ( x _ { t } – sqrt { overline { alpha } _ { t } } x _ { 0 } ) ^ { 2 } } { 2 ( 1 – overline { alpha } _ { t } ) }]}
(59)
=exp{−12[(xt−αtxt−1)21−αt+(xt−1−α‾t−1×0)21−α‾t−1−(xt−α‾tx0)21−α‾t]}= exp { -frac{1}{2} [frac { ( x _ { t } – sqrt { alpha _ { t } } x _ { t – 1 } ) ^ { 2 } } { 1 – alpha _ { t } }+ frac { ( x _ { t – 1 } – sqrt { overline { alpha } _ { t – 1 } } x _ { 0 } ) ^ { 2 } } { 1 – overline { alpha } _ { t – 1 } } – frac { ( x _ { t } – sqrt { overline { alpha } _ { t } } x _ { 0 } ) ^ { 2 } } { 1 – overline { alpha } _ { t } }]}
(60)
=exp{−12[(−2αtxtxt−1+αtxt−12)1−αt+(xt−12−2α‾t−1xt−1×0)1−α‾t−1+C(xt,x0)]}= exp { -frac{1}{2} [frac { ( – 2 sqrt { alpha _ { t } } x _ { t } x _ { t – 1 } + alpha _ { t } x _ { t – 1 } ^ { 2 } ) } { 1 – alpha _ { t } } + frac { ( x _ { t – 1 } ^ { 2 } – 2 sqrt {overline alpha _ { t – 1 } } x _ { t – 1 } x _ { 0 } ) } { 1 – overline { alpha } _ { t – 1 } } + C ( x _ { t } , x _ { 0 } )]}
(61)
∝exp{−12[2αtxtxt−11−αt+αtxt−121−αt+xt−121−α‾t−1−2αt−1xt−1×01−α‾t−1+C(xt,x0)]}propto exp { -frac{1}{2} [frac { 2 sqrt { alpha _ { t } } x _ { t } x _ { t – 1 } } { 1 – alpha _ { t } } + frac { alpha _ { t } x _ { t – 1 } ^ { 2 } } { 1 – alpha _ { t } } + frac { x _ { t – 1 } ^ { 2 } } { 1 – overline { alpha } _ { t – 1 } } – frac { 2 sqrt { alpha _ { t – 1 } } x _ { t – 1 } x _ { 0 } } { 1 – overline { alpha } _ { t – 1 } }+ C ( x _ { t } , x _ { 0 } )]}
(62)
=exp{−12[(αt1−αt+11−α‾t−1)xt−12−2(αtxt1−αt+αt−1×01−α‾t−1)xt−1+C(xt,x0)]}=exp { -frac{1}{2} [( frac { alpha _ { t } } { 1 – alpha _ { t } } + frac { 1 } { 1 – overline { alpha } _ { t – 1 } } ) x _ { t – 1 } ^ { 2 } – 2 ( frac { sqrt { alpha _ { t } } x _ { t } } { 1 – alpha _ { t } } + frac { sqrt { alpha _ { t – 1 } } x _ { 0 } } { 1 – overline { alpha } _ { t – 1 } } ) x _ { t – 1 } + C ( x _ { t } , x _ { 0 } )]}
(63)
=exp{−12[αt(1−α‾t−1)+1−αt(1−αt−1)xt−12−2(αtxt1−αt+α‾t−1×01−α‾t−1)xt−1+C(xt,x0)]}=exp { -frac{1}{2} [frac { alpha_ { t } ( 1 – overline { alpha } _ { t – 1 } ) + 1 – alpha _ { t } } { ( 1 – alpha _ { t – 1 } ) } x _ { t – 1 } ^ { 2 } – 2 ( frac { sqrt { alpha _ { t } } x _ { t } } { 1 – alpha _ { t } } + frac { sqrt { overlinealpha _ { t – 1 } } x _ { 0 } } { 1 – overline { alpha } _ { t – 1 } } ) x _ { t – 1 } + C ( x _ { t } , x _ { 0 } )]}
(64)
=exp{−12[αt−α‾t+1−αt(1−αt)(1−α‾t−1)xt−12−2(αtxt1−αt+α‾t−1×01−α‾t−1)xt−1+C(xt,x0)]}=exp { -frac{1}{2} [frac { alpha _ { t } – overline { alpha } _ { t } + 1 – alpha _ { t } } { ( 1 – alpha _ { t } ) ( 1 – overline { alpha } _ { t – 1 } ) } x _ { t – 1 } ^ { 2 } – 2 ( frac { sqrt { alpha _ { t } } x _ { t } } { 1 – alpha _ { t } } + frac { sqrt { overlinealpha _ { t – 1 } } x _ { 0 } } { 1 – overline { alpha } _ { t – 1 } } ) x _ { t – 1 }+ C ( x _ { t } , x _ { 0 } )]}
(65)
=exp{−12[1−α‾t(1−αt)(1−α‾t−1xt−12−2(αtxt1−αt+α‾t−1×01−α‾t−1)xt−1+C(xt,x0)]}=exp { -frac{1}{2} [frac { 1 – overline { alpha } _ { t } } { ( 1 – alpha _ { t } ) ( 1 – overline { alpha } _ { t – 1 } } x _ { t – 1 } ^ { 2 } – 2 ( frac { sqrt { alpha _ { t } } x _ { t } } { 1 – alpha _ { t } } + frac { sqrt { overlinealpha _ { t – 1 } } x _ { 0 } } { 1 – overline { alpha } _ { t – 1 } } ) x _ { t – 1 }+ C ( x _ { t } , x _ { 0 } )]}
(66)
=exp{−12(1−α‾t(1−αt)(1−α‾t−1))[xt−12−2(αtxt1−αt+α‾t−1×01−α‾t−1)1−α‾t(1−αt)(1−α‾t−1)xt−1+C(xt,x0)]}=exp { -frac{1}{2}left ( frac { 1 – overlinealpha _ { t } } { left ( 1 – alpha _ { t } right ) left ( 1 – overline { alpha } _ { t – 1 } right ) } right ) [x _ { t – 1 } ^ { 2 } -2 frac { ( frac { sqrt { alpha _ { t } } x _ { t } } { 1 – alpha _ { t } } + frac { sqrt { overlinealpha _ { t – 1 } } x _ { 0 } } { 1 – overlinealpha _ { t-1 } ) } } { frac { 1- overlinealpha_{t} } { ( 1 – alpha _ { t } ) ( 1 – overline { alpha } _ { t – 1 } ) } } x _ { t – 1 }+ C ( x _ { t } , x _ { 0 } )]}
(67)
=exp{−12(1−α‾t(1−αt)(1−α‾t−1))[xt−12−2(αtxt1−αt+α‾t−1×01−α‾t−1)(1−αt)(1−α‾t−1)1−α‾txt−1+C(xt,x0)]}=exp { -frac{1}{2}left ( frac { 1 – overlinealpha _ { t } } { left ( 1 – alpha _ { t } right ) left ( 1 – overline { alpha } _ { t – 1 } right ) } right ) [x _ { t – 1 } ^ { 2 } – 2 frac { ( frac { sqrt { alpha _ { t } } x _ { t } } { 1 – alpha _ { t } } + frac { sqrt { overlinealpha _ { t – 1 } } x _ { 0 } } { 1 – overline { alpha } _ { t – 1 } } ) ( 1 – alpha _ { t } ) ( 1 – overline { alpha } _ { t – 1 } ) } { 1 – overline { alpha } _ { t } } x _ { t – 1 }+ C ( x _ { t } , x _ { 0 } )]}
(68)
=exp{−12(1(1−αt)(1−α‾t−1)1−α‾t)[xt−12−2αt(1−α‾t−1)xt+α‾t−1(1−αt)x01−α‾txt−1+C(xt,x0)2]}=exp { – frac { 1 } { 2 } ( frac { 1 } { frac { ( 1 – alpha _ { t } ) ( 1 – overline { alpha } _ { t – 1 } ) } { 1 – overline { alpha } _ { t } } } )[x _ { t – 1 } ^ { 2 } – 2 frac { sqrt { alpha _ { t } } ( 1 – overline { alpha } _ { t – 1 } ) x _ { t } + sqrt { overline { alpha } _ { t – 1 } } ( 1 – alpha _ { t } ) x _ { 0 } } { 1 – overline { alpha } _ { t } } x _ { t – 1 }+ sqrt{C ( x _ { t } , x _ { 0 } )}^{2}]}
(69)
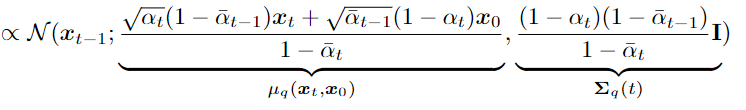
Trong đó C(xt,xo){C(x_{t},x_{o})} bằng với μq(xt,x0)2{mu_q(x_{t},x_{0})}^{2} bình phương hãy để ý vế trái phương trình (68) là một hằng đẳng thức. Từ đó ta biết được rằng
xt−1∼q(xt−1∣xt,x0)x _ { t – 1 } sim q ( x _ { t – 1 } | x _ { t , } x _ { 0 } )
với trung bình mẫu μq(xt,x0){mu_q(x_{t},x_{0})} và phương sai ∑q(t){sum_{q}(t)}. Ta có thể viết lại ∑q(t)=σq2(t){{sum_{q}(t)} = {sigma_{q}^{2}(t)}}
(70)
σq2(t)=(1−αt)(1−α‾t−t)1−α‾tsigma _ { q } ^ { 2 } ( t ) = frac { ( 1 – alpha _ { t } ) ( 1 – overline { alpha } _ { t – t } ) } { 1 – overline { alpha } _ { t } }
Mục tiêu quan trọng thứ hai chính là denoising matching term đây chính là điều mà ta muốn khám phá. Chúng ta sẽ xét khoảng cách phân phối giữa khuyến tán thuận noise layer ẩn và khuyến tạn đảo ngược . Mọi thứ nằm trong phương trình (33) denoising matching term .
Chúng ta sẽ tối ưu khoảng cách giữa hai phân phối đó ( lưu ý quan trọng là hai khoảng cách đó có cùng chiều với nhau ta giả sử ký hiệu là d) do đều quan tâm đến xt{x_{t}} các tiềm ẩn dữ liệu noise.
(71)
DKL(N(x;μx,Σx)∥N(y;μy,Σy))=12[log∣Σy∣∣Σx∣−d+tr(Σy−1Σx)+(μy−μx)TΣy−1(μy−μx)]D _ { K L } ( N ( x ; mu _ { x } , Sigma _ { x } ) | N ( y ; mu _ { y } , Sigma _ { y } ) ) = frac { 1 } { 2 } [ log frac { | Sigma _ { y } | } { | Sigma _ { x } | } – d + operatorname { t r } ( Sigma _ { y } ^ { – 1 } Sigma _ { x } ) + ( mu _ { y } – mu _ { x } ) ^ { T } Sigma _ { y } ^ { – 1 } ( mu _ { y } – mu _ { x } ) ]
tr : Trace (vết matrix) là tổng các đường chéo trong matrix vuông.
Từ đó ta sẽ tối ưu hóa khoảng cách giữa khuyến tán thuận noise xt{x_{t}} và khuyến tán ngược tiềm ẩn noise xt{x_{t}}.
(72)
argminDKLθ(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))underset { theta } { arg min D _ { KL } } ( q ( x _ { t – 1 } | x _ { t } , x _ { 0 } ) | p _ { theta } ( x _ { t – 1 } | x _ { t } ) )
(73)
=argθminDKL(N(xt−1;μq,Σq(t))∥N(xt−1;μθ,Σq(t)))= underset {theta} arg min D _ { K L } ( N ( x _ { t – 1 } ; mu _ { q } , Sigma _ { q } ( t ) ) | N ( x _ { t – 1 } ; mu _ { theta } , Sigma _ { q } ( t ) ) )
(74) Nên nhớ diffussion model có quy luật bảo toàn phương sai.
=argθmin12[log∣Σq(t)∣∣Σq(t)∣−d+tr(Σq(t)−1Σq(t))+(μθ−μq)TΣq(t)−1(μθ−μq)]= underset{theta} arg min frac { 1 } { 2 } [ log frac { | Sigma _ { q } ( t ) | } { | Sigma _ { q } ( t ) | } – d + operatorname { t r } ( Sigma _ { q } ( t ) ^ { – 1 } Sigma _ { q } ( t ) ) + ( mu _ { theta } – mu _ { q } ) ^ { T } Sigma _ { q } ( t ) ^ { – 1 } ( mu _ { theta } – mu _ { q } ) ]
(75) Nên nhớ A−1.A=I{A^{-1}.A = I} suy ra trace(I)=dtrace(I) = d
=argminθ12[log1−d+d+(μθ−μq)TΣq(t)−1(μθ−μq)]= underset{theta} {arg min} frac { 1 } { 2 } [ log 1 – d + d + ( mu _ { theta } – mu _ { q } ) ^ { T } Sigma _ { q } ( t ) ^ { – 1 } ( mu _ { theta } – mu _ { q } ) ]
(76)
=argminθ12[(μθ−μq)TΣq(t)−1(μθ−μq)]= underset{theta} {arg min} frac { 1 } { 2 } [ ( mu _ { theta } – mu _ { q } ) ^ { T } Sigma _ { q } ( t ) ^ { – 1 } ( mu _ { theta } – mu _ { q } ) ]
(77)
=argθmin12[(μθ−μq)T(σq2(t)I)−1(μθ−μq)]= underset{theta} arg min frac { 1 } { 2 } [ ( mu _ { theta } – mu _ { q } ) ^ { T } ( sigma _ { q } ^ { 2 } ( t ) I ) ^ { – 1 } ( mu _ { theta } – mu _ { q } ) ]
(78)
=argθmin12σq2(t)[∥μθ−μq∥22]= underset{theta} arg min frac { 1 } { 2 sigma _ { q } ^ { 2 } ( t ) } [ | mu _ { theta } – mu _ { q } | _ { 2 } ^ { 2 } ]
Trong đó μq{mu_q} viết tắt của μq(xt,x0){mu_q(x_{t},x_{0})} và μθ{mu_{theta}} viết tắt của μq(xt,t){mu_q(x_{t},t)} . Nói cách khác ta muốn tối ưu khoảng cách giữa μq{mu_q} và μθ{mu_{theta}} .
Dựa vào phương trình (69) ta biết:
(79)
μq(xt,x0)=αt(1−α‾t−1)xt+α‾t−1(1−αt)x01−α‾tmu _ { q } ( x _ { t } , x _ { 0 } ) = frac { sqrt { alpha _ { t } } ( 1 – overline { alpha } _ { t – 1 } ) x _ { t } + sqrt { overlinealpha _ { t – 1 } } ( 1 – alpha _ { t } ) x _ { 0 } } { 1 – overline { alpha } _ { t } }
Từ đó suy ra:
(80)
μθ(xt,t)=αt(1−α‾t−1)xt+α‾t−1(1−αt)x^θ(xt,t)1−αt‾mu _ { theta } ( x _ { t } , t ) = frac { sqrt { alpha _ { t } } ( 1 – overline { alpha } _ { t – 1 } ) x _ { t } + sqrt { overline { alpha } _ { t – 1 } } ( 1 – alpha _ { t } ) hat { x } _ { theta } ( x _ { t } , t ) } { 1 – overline { alpha _ { t } } }
xθ(xt,t){x_{theta} (x_{t}, t)} được học bởi một mạng nơron tìm cách dự đoán xθ{x_{theta}} từ ảnh nhiễu xt{x_{t}} và chỉ số thời gian tt. Ta sẽ tiếp tục tối ưu hóa tiếp phương trình (72)
argminDKLθ(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))underset { theta } { arg min D _ { KL } } ( q ( x _ { t – 1 } | x _ { t } , x _ { 0 } ) | p _ { theta } ( x _ { t – 1 } | x _ { t } ) )
(81)
=argθminDKL(N(xt−1;μq,Σq(t))∥N(xt−1;μθ,Σq(t)))= underset{theta} arg min D _ { K L } ( N ( x _ { t – 1 } ; mu _ { q } , Sigma _ { q } ( t ) ) quad | N ( x _ { t – 1 } ; mu _ { theta } , Sigma _ { q } ( t ) ) )
(82)
=argminθ12σq2(t)[∥αt(1−α‾t−1)xt+α‾t−1(1−αt)x^θ(xt,t)1−α‾t−αt(1−α‾t−1)xt+α‾t−1(1−αt)x01−αt‾∥22]= arg min _ { theta } frac { 1 } { 2 sigma _ { q } ^ { 2 } ( t ) } [| frac { sqrt { alpha _ { t } } ( 1 – overline { alpha } _ { t – 1 } ) x _ { t } + sqrt { overline { alpha } _ { t – 1 } } ( 1 – alpha _ { t } ) hat { x } _ { theta } ( x _ { t } , t ) } { 1 – overline { alpha } _ { t } } – frac { sqrt { alpha _ { t } } ( 1 – overline { alpha } _ { t – 1 } ) x _ { t } + sqrt { overline { alpha } _ { t – 1 } } ( 1 – alpha _ { t } ) x _ { 0 } } { 1 – overline { alpha _ { t } } } | _ { 2 } ^ { 2 }]
(83)
=argminθ12σq2(t)[ ∣α‾t−1(1−αt)x^θ(xt,t)1−αt‾−α‾t−1(1−αt)x01−α‾t∣∣22]= arg min _ { theta } frac { 1 } { 2 sigma _ { q } ^ { 2 } ( t ) }[ | frac { sqrt { overline { alpha } _ { t } – 1 } ( 1 – alpha _ { t } ) hat { x } _ { theta } ( x_ { t } , t ) } { 1 – overline { alpha _ { t } } } – frac { sqrt { overline { alpha } _ { t – 1 } } ( 1 – alpha_ { t } ) x _ { 0 } } { 1 – overline { alpha } _ { t } } | | _ { 2 } ^ { 2 }]
(84)
=argminθ12σq2(t)α‾t−1(1−αt)2(1−α‾t)2[∥x^θ(xt,t)−x0∥22]= arg min _ { theta } frac { 1 } { 2 sigma _ { q } ^ { 2 } ( t ) } frac { overline { alpha } _ { t – 1 } ( 1 – alpha _ { t } ) ^ { 2 } } { ( 1 – overline { alpha } _ { t } ) ^ { 2 } } [ | hat { x } _ { theta } ( x _ { t } , t ) – x _ { 0 } | _ { 2 } ^ { 2 } ]
Khi đó optimizer của khoảng cách sẽ viết ngắn gọn thành là :
(85)
argminθEt∼U{2,T}[Eq(xt∣x0)[DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))]]underset { theta } { arg min } E _ { t sim U { 2 , T } } { } [ E _ { q ( x _ { t } | x _ { 0 } ) } [ D _ { K L } ( q ( x _ { t – 1 } | x _ { t } , x _ { 0 } ) | p _ { theta } ( x _ { t – 1 } | x _ { t } ) ) ] ]
1.4 SNR : Tỷ Lệ Nhiễu
Tuy nhiên việc tính toán các trung bình và phương sai có parameter α{alpha} có rất nhiều cách thực hiện khác nhau . Như dựa trên điểm số score-based,..vv nhưng ở đây chúng ta sẽ giới thiệu về dựa trên tỷ lệ nhiễu của ảnh:
Thay thế phương trình (70) vào (84):
(86)
12σq2(t)α‾t−1(1−αt)2(1−α‾t)2[∥x^θ(xt,t)−x0∥22]=12(1−αt)(1−α‾t−1)αtα‾t−1(1−αt)2(1−α‾t)2[∥x^θ(xt,t)−x0∥22]frac { 1 } { 2 sigma _ { q } ^ { 2 } ( t ) } frac { overline { alpha } _ { t – 1 } ( 1 – alpha _ { t } ) ^ { 2 } } { ( 1 – overline { alpha } _ { t } ) ^ { 2 } } [ | hat { x } _ { theta } ( x _ { t } , t ) – x _ { 0 } | _ { 2 } ^ { 2 } ] =frac { 1 } { 2 { frac { (1 – alpha _ { t } ) ( 1 – overline { alpha } _ { t – 1 } ) } { alpha _ { t } } } } frac { overline { alpha } _ { t – 1 } ( 1 – alpha _ { t } ) ^ { 2 } } { ( 1 – overline { alpha } _ { t } ) ^ { 2 } } [ | hat { x } _ { theta } ( x _ { t } , t ) – x _ { 0 } | _ { 2 } ^ { 2 } ]
(87)
=121−α‾t(1−αt)(1−α‾t−1)α‾t−1(1−αt)2(1−α‾t)2[∥x^θ(xt,t)−x0∥22]= frac { 1 } { 2 } frac { 1 – overline { alpha } _ { t } } { ( 1 – alpha _ { t } ) ( 1 – overline { alpha } _ { t – 1 } ) } frac { overline { alpha } _ { t – 1 } ( 1 – alpha _ { t } ) ^ { 2 } } { ( 1 – overline { alpha } _ { t } ) ^ { 2 } } [ | hat { x } _ { theta } ( x _ { t } , t ) – x _ { 0 } | _ { 2 } ^ { 2 } ]
(88)
=12α‾t−1(1−αt)(1−α‾t−1)(1−α‾t)[∥x^θ(xt,t)−x0∥22]= frac { 1 } { 2 } frac { overline { alpha } _ { t – 1 } ( 1 – alpha _ { t } ) } { ( 1 – overline { alpha } _ { t – 1 } ) ( 1 – overline { alpha } _ { t } ) } [ | hat { x } _ { theta } ( x _ { t } , t ) – x _ { 0 } | _ { 2 } ^ { 2 } ]
(89)
=12α‾t−1−α‾t(1−α‾t−1)(1−α‾t)[∥x^θ(xt,t)−x0∥22]= frac { 1 } { 2 } frac { overline { alpha } _ { t – 1 } – overline { alpha } _ { t } } { ( 1 – overline { alpha } _ { t – 1 } ) ( 1 – overline { alpha } _ { t } ) } [ | hat { x } _ { theta } ( x _ { t } , t ) – x _ { 0 } | _ { 2 } ^ { 2 } ]
(90)
=12α‾t−1−α‾t−1α‾t+α‾t−1(1−α‾t−1)(1−α‾t)[∥x^θ(xt,t)−x0∥22]= frac { 1 } { 2 } frac { overline { alpha } _ { t – 1 } – overline { alpha } _ { t – 1 } overline { alpha } _ { t } + overline { alpha } _ { t – 1 } } { ( 1 – overline { alpha } _ { t – 1 } ) ( 1 – overline { alpha } _ { t } ) } [ | hat { x } _ { theta } ( x _ { t } , t ) – x _ { 0 } | _ { 2 } ^ { 2 } ]
(91)
=12α‾t−1(1−α‾t)−α‾t(1−α‾t−1)(1−α‾t−1)(1−α‾t)[∥x^θ(xt,t)−x0∥22]= frac { 1 } { 2 } frac { overline { alpha } _ { t – 1 } ( 1 – overline { alpha } _ { t } ) – overline { alpha } _ { t } ( 1 – overline { alpha } _ { t – 1 } ) } { ( 1 – overline { alpha } _ { t – 1 } ) ( 1 – overline { alpha } _ { t } ) } [ | hat { x } _ { theta } ( x _ { t } , t ) – x _ { 0 } | _ { 2 } ^ { 2 } ]
(92)
=12(α‾t−1(1−α‾t)(1−α‾t−1)(1−α‾t)−α‾t(1−α‾t−1)(1−α‾t−1)(1−α‾t))[∥x^θ(xt,t)−x0∥22]= frac { 1 } { 2 } ( frac { overline { alpha } _ { t – 1 } ( 1 – overline { alpha } _ { t } ) } { ( 1 – overline { alpha } _ { t – 1 } ) ( 1 – overline { alpha } _ { t } ) } – frac { overline { alpha } _ { t } ( 1 – overline { alpha } _ { t – 1 } ) } { ( 1 – overline { alpha } _ { t – 1 } ) ( 1 – overline { alpha } _ { t } ) } )[ | hat { x } _ { theta } ( x _ { t } , t ) – x _ { 0 } | _ { 2 } ^ { 2 } ]
(93)
=12(α‾t−11−α‾t−1−α‾t1−α‾t)[∥x^θ(xt,t)−x0∥22]= frac { 1 } { 2 } ( frac { overline { alpha } _ { t – 1 } } { 1 – overline { alpha } _ { t – 1 } } – frac { overline { alpha } _ { t } } { 1 – overline { alpha } _ { t } } )[ | hat { x } _ { theta } ( x _ { t } , t ) – x _ { 0 } | _ { 2 } ^ { 2 } ]
Tỷ lệ nhiễu trong đoạn này ta sẽ sử dụng tỷ lệ nhiễu để giảm thiểu phân kỳ KL giữa chúng , như đã biết từ (*) và (55) và SNR=μ2σ2{SNR = {frac{mu^{2}}{sigma^{2}}}} ta viết lại:
(94)
SNR(t)=α‾t1−α‾toperatorname { S N R } ( t ) = frac { overline { alpha } _ { t } } { 1 – overline { alpha } _ { t } }
Áp dụng vào (93) suy ra được:
(95)
12σq2(t)α‾t−1(1−αt)2(1−α‾t)2[∥x^θ(xt,t)−x0∥22]=12(SNR(t−1)−SNR(t))[∥x^θ(xt,t)−x0∥22]frac { 1 } { 2 sigma _ { q } ^ { 2 } left ( t right ) } frac { overline { alpha } _ { t – 1 } left ( 1 – alpha _ { t } right ) ^ { 2 } } { left ( 1 – overline { alpha } _ { t } right ) ^ { 2 } } left [ | hat { x } _ { theta } left ( x _ { t } , t right ) – x _ { 0 } | _ { 2 } ^ { 2 } right ] = frac { 1 } { 2 } ( operatorname { S N R } ( t – 1 ) – operatorname { S N R } ( t ) ) [ | hat { x } _ { theta } ( x _ { t } , t ) – x _ { 0 } | _ { 2 } ^ { 2 } ]
Như tên của nó, SNR đại diện cho tỷ lệ giữa tín hiệu gốc và lượng nhiễu hiện có; SNR cao hơn biểu thị nhiều tín hiệu hơn và SNR thấp hơn biểu thị nhiều nhiễu hơn. Trong mô hình khuếch tán, chúng tôi yêu cầu SNR giảm đơn điệu khi bước thời gian t tăng lên; điều này chính thức hóa khái niệm rằng đầu vào xáo trộn xt ngày càng trở nên ồn ào theo thời gian, cho đến khi nó trở nên giống hệt với một Gaussian tiêu chuẩn tại t = T
Dựa trên sự đơn giảnPhương trình 95, chúng ta có thể học trực tiếp SNR tại mỗi bước thời gian bằng cách sử dụng mạng nơ-ron và tìm hiểu nó cùng với mô hình khuếch tán. Vì SNR phải giảm đơn điệu theo thời gian, chúng ta có thể biểu diễn nó là:
(96)
SNR^(t)=exp(−ωη(t))hat { mathrm { S N R } } ( t ) = exp ( – omega _ { eta } ( t ) )
Trong đó ωη (t) mạng nơ ron theo thời gian t với tham số n . Tối ưu hóa tham số n dựa trên phương trình (94) và (96) Khi đó ta có thể tính ra các trung bình mẫu α‾{overline alpha} và phương sai 1−α‾{1 – overline alpha} .
(97)
α‾t1−α‾t=exp(−ωη(t))frac { overline { alpha } _ { t } } { 1 – overline { alpha } _ { t } } = exp ( – omega _ { eta } ( t ) )
Suy ra trung bình có tham số để học là:
α‾t=exp(−ωη(t))(1−α‾t)overline { alpha } _ { t } = exp ( – omega _ { eta } ( t ) )({ 1 – overline { alpha } _ { t } })
và phương sai để học là:
1−α‾t=exp(−ωη(t))(α‾t){ 1 – overline { alpha } _ { t } } = exp ( – omega _ { eta } ( t ) )(overline { alpha } _ { t })
2. Tổng Kết
(97)
Nhìn lại tất cả mọi thứ kết hơp phương trình (33) ta có:
Đo
argmaxθEq(x1∣x0)[logpθ(x0∣x1)]−DKL(q(xT∣x0)∥p(xT))underset { theta } { arg max } E_{ q left ( x _ { 1 } | x _ { 0 } right ) } [ log p _ { theta } ( x_{0} | x_{1} ) ] – D _ { K L } ( q _ { } ( x_{T} | x_{0} ) | p ( x_{T} ) )
(98)
Đoạn 2 trong phương trình (33) do không có tham số cho nên ta bỏ qua chúng.
DKL(q(xT∣x0)∥p(xT))D _ { K L } ( q ( x _ { T } | x _ { 0 } ) | p ( x _ { T } ) )
(99)
Đoạn 3: Được mô tả trong phương trình số (85):
argminθEt∼U{2,T}[Eq(xt∣x0)[DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))]]underset { theta } { arg min } E _ { t sim U { 2 , T } } { } [ E _ { q ( x _ { t } | x _ { 0 } ) } [ D _ { K L } ( q ( x _ { t – 1 } | x _ { t } , x _ { 0 } ) | p _ { theta } ( x _ { t – 1 } | x _ { t } ) ) ] ]
Đây là cơ sở căn bản của hàm Loss bạn có thể sẽ thấy ngặc nhiên so với paper gốc của Diffussion model, tuy nhiên trong series 3 bạn sẽ học cách triển khai chúng và gới gọn hàm loss hơn nữa. Hơn nữa giờ chúng ta chỉ có biết mỗi quy trình khuyến tán thuận và reparameter trick còn việc lấy sample khuyến tạn ngược ta chưa tính . Mọi thứ sẽ nằm trong series 3
Tóm tắt tổng kết
- Mô hình khuếch tán của chúng tôi được tham số hóa dưới dạng chuỗi Markov , có nghĩa là các xt{x_{t}} noise của chúng tôi chỉ phụ thuộc vào bước thời gian trước (hoặc sau).
2 .Các phân phối chuyển tiếp trong chuỗi Markov là Gaussian , trong đó quá trình thuận yêu cầu một lịch trình phương sai và các tham số của quá trình ngược lại được học ở đây là alpha - Quá trình khuếch tán đảm bảo rằng xT{x_{T}} được phân phối tiệm cận như một Gaussian đẳng hướng cho TT đủ lớn
- Trong trường hợp của chúng tôi, lịch trình phương sai đã được cố định , nhưng nó cũng có thể được học. Đối với các lịch trình cố định, việc tuân theo một tiến trình hình học có thể mang lại kết quả tốt hơn so với một tiến trình tuyến tính. Trong cả hai trường hợp, các phương sai thường tăng dần theo thời gian trong chuỗi
- Mô hình khuếch tán có tính linh hoạt cao và cho phép sử dụng bất kỳ kiến trúc nào có kích thước đầu vào và đầu ra giống nhau. Tiêu biểu Unet
- Mục tiêu gồm có 2 thứ là argmin khoảng cách giữa noise khuyến tán thuận xt{x_{t}} và decoder khuyến tán ngược xt{x_{t}} và argmax làm sao để log sát xuất khuyến tán ngược giữa x0{x_{0}} lớn nhất dựa trên noise decoder.
- Có nhiều cách thưc để tối ưu hóa tham số ngoài SNR ví dụ như dựa trên điểm số ,..vv tuy nhiên ở đây chúng ta chỉ nói về SNR giới hạn trong series 2 vì chúng đã quá dài.
Sau đây là kết thúc series 2 rất rất dài , khó có thể nói ngắn gọn được . Series 3 sẽ bao gồm nhiều cách huấn luyện và mô hình dựa trên điểm số , động lực học , có lẽ có thể dài hơn nhiều so vs series 2.
Tài liệu tham khảo:
- https://arxiv.org/abs/2208.11970
- https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
- https://www.assemblyai.com/blog/diffusion-models-for-machine-learning-introduction/#:~:text=Diffusion Models are generative models%2C meaning that they are used,by reversing this noising process.
- https://paperswithcode.com/paper/diffusion-models-a-comprehensive-survey-of
Cảm ơn các bạn. Mong mọi người tiếp tục ủng hộ series này , nếu có thắc mắc với series này vui lòng để lại bình luận phía dưới. !!
Nguồn: viblo.asia