Mở đầu
Push notification là bài toán anh em dev thường xuyên gặp với những ứng dụng sử dụng nhiều nền tảng như Mobile, Window…
Bài toán này không khó, vấn đề gặp phải khi push số lượng lớn notification cần phải đảm bảo dữ liệu đúng, đầy đủ. Cùng với đó, các chức năng khác của hệ thống cũng phải hoạt động bình thường.
Mình đã từng gặp những hệ thống die khi chạy chức năng push notification (nguyên nhân sẽ chia sẻ ở cuối bài viết). Vì vậy ở đây mình chia sẻ 1 case study về việc push ~ 15 triệu notification trong khoảng thời gian < 1h (không đề cập đến bài toán sử dụng topic pub-sub nhé). Thiết kế này đang cố gắng đảm bảo được 2 yếu tố: tất cả các chức năng hoạt động bình thường + tối ưu chi phí hoạt động.
Mình sẽ không giới thiệu chi tiết từng dịch vụ đã sử dụng, vì như vậy sẽ rất dài. Bài viết sẽ hiệu quả nhất đối với các bạn developer đã từng tiếp xúc với AWS, hiểu cơ bản các dịch vụ dùng để làm gì. Nếu chưa từng làm việc với AWS, các bạn có thể đọc thêm 1 số khái niệm mình refer dưới đây:
Amazon Elastic Container Service: https://aws.amazon.com/ecs/
Amazon RDS (Database service): https://aws.amazon.com/rds/
AWS Lambda: https://aws.amazon.com/lambda/
Amazon Simple Notification Service: https://aws.amazon.com/sns
Amazon Simple Queue Service: https://aws.amazon.com/sqs/
AWS Cloudwatch Alarm: https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html
Do một số vấn đề về bảo mật, mình cũng không thể chia sẻ sâu hơn được về hệ thống được, chỉ nêu ra được overview và ý tưởng. Phần Design diagram cũng đã được tối giản để tập trung duy nhất vào giải pháp. Đây có thể không phải là 1 tài liệu đủ để các bạn áp dụng được luôn, nhưng là 1 hướng để chúng ta đi theo giải quyết bài toán.
Giới thiệu bài toán
Như đã trình bày ở phần mở đầu, bài viết này sẽ trình bày về giải pháp để thực hiện push 15 triệu notification trong thời gian < 1h.
Khách hàng của mình có 1 sản phẩm Global chạy trên khoảng 20 triệu máy tính. Theo tính toán, trong khoảng thời gian 1h, tối đa sẽ có 15M notifications được push. Hệ thống push notification này được trên khai trên cùng 1 hệ thống khác đang chạy production, nên phải đáp ứng đủ 2 yêu cầu
- Performance đáp ứng được đúng yêu cầu: Bắt đầu thực hiện targeting trước12h và phải hoàn thành trước giờ push (có 12h để thực hiện targeting). Push 15M notifications hoàn thành trong 1h. Trong trường hợp push thất bại phải lưu lại lịch sử trong DB để có thể check lại sau.
- Đảm bảo không ảnh hưởng đến hệ thống cũ đang chạy
Bài viết này sẽ tập trung giải quyết vấn đề số 1.
Giải quyết vấn đề
Cụ thể hơn trong hệ thống của mình cần phải xử lý 3 vấn đề chính:
- Targeting – Xác định tệp khách hàng cần gửi thông báo
- Push – Gửi thông báo đến thiết bị
- Xử lý lỗi (trong trường hợp push bị lỗi)
Trước khi giải quyết từng vấn đề, hãy đến với thiết kế tổng quát việc push notification này nhé
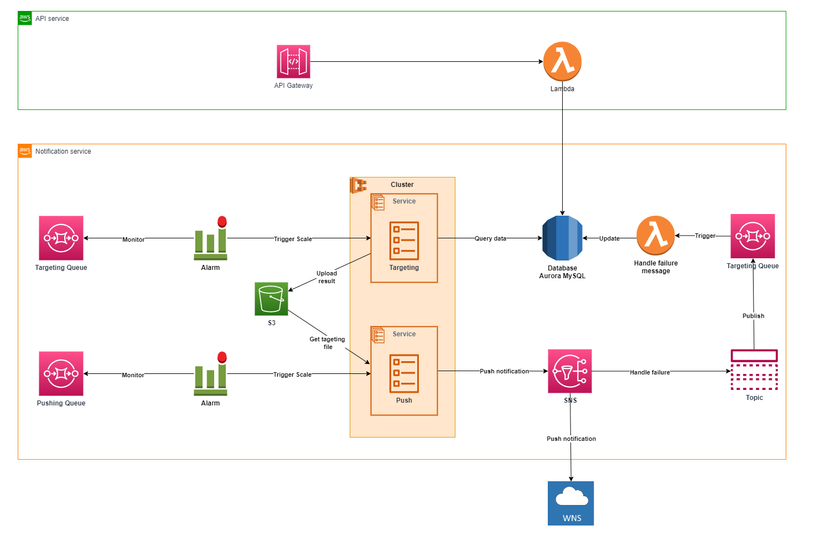
Overview
Hệ thống đang dùng:
- Ngôn ngữ: Java (core, theo yêu cầu của KH)
- Các dịch vụ AWS: ECS, ECR, S3, SQS, SNS, RDS… Đối với SNS, hãy phân biệt SNS Application platform (dùng đề quản lý, push notification đến notification provider) và SNS Topic (Publish – Subscribe)
- Notification service: Push cho máy window nên phải dùng qua WNS https://docs.microsoft.com/en-us/windows/apps/design/shell/tiles-and-notifications/windows-push-notification-services–wns–overview
- Other tool: Docker Engine …
Khi nhìn vào diagram phía trên các bạn có thể thấy dùng ECS Service và Cloudwath Alarm để thực hiện scale. Thông thường khi scale cho API thì chúng ta thường chỉ định autoscale dựa trên CPU, Memory … Tuy nhiên ở đây mình sẽ cài đặt scale dựa trên số lượng message trong SQS.
Ví dụ:
- Khi số lượng message visible (visible là message chưa được xử lý) >= 1 trong 1 phút -> Thực hiện add thêm 1 instance
- Khi số lượng message invisible (message đang được xử lý) < 1 trong vòn 5 phút -> Thực hiện giảm instance.
Đây là ví dụ cho việc scale số lượng instance để đáp ứng được lượng workload cần thiết cũng như tiết kiệm chi phí. Khi chúng ta hiểu được cơ chế scale thì việc còn lại chỉ là quyết định các con số cho phù hợp (thêm/bớt bao nhiền instance, giảm bao nhiêu instance, các giá trị khác như threadhold, period, colddown.. cũng cần tính toán phù hợp với các bài toán khác nhau)
Nguyên tắc scale này được áp dụng chung cho cả việc targeting và việc push.
Notification service ở một góc nhìn khác:
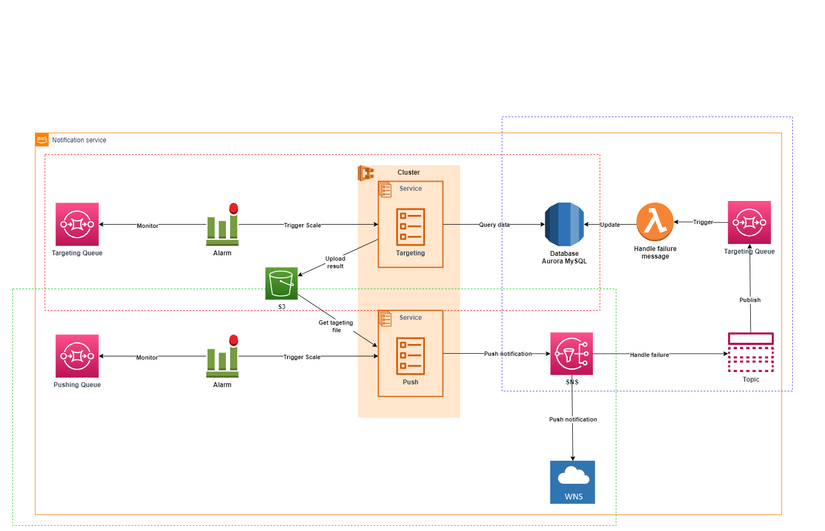
- Màu đỏ : Targeting
- Màu xanh lá: Push
- Màu xanh dương: Xử lý push thất bại
Targeting
Đầu tiên chúng ta đến với phần targeting. Phần này không khó về mặt logic. Tuy nhiên chúng ta cần xử lý khéo léo đối với số lượng record trong DB lớn.
Step thực hiện sẽ là:
- Khi có 1 notification đến thời gian targeting, gửi 1 message vào Targeting Queue chứa thông tin của notification đó
- Alarm dựa vào metric ApproximateNumberOfMessagesVisible, nếu có message trong queue sẽ trigger scale out để thêm 1 instance mới
- Instance khởi chạy lên, lấy message từ queue và thực hiện query đến DB, khi này ApproximateNumberOfMessagesVisible = 0, ApproximateNumberOfMessagesNotVisible = 1
- Sau khi targeting xong, instance xóa message trong queue, tổng hợp thành nhiều file json(10.000 records/file), lưu lại vào S3
- Sau khi xóa message, ApproximateNumberOfMessagesNotVisible (số lượng message đang xử lý) = 0, Alarm sẽ thực hiện trigger scale in.
Lưu ý với bài toán targeting:
- DB bắt buộc phải đánh index hợp lí, vì thường bài toán targeting sẽ lọc theo rất nhiều điều kiện. Dự án của mình targeting chỉ có 8 điều kiện, chưa phải là nhiều so với các dự án khác.
- Luôn luôn phải tách biệt DB Read – Write, với việc targeting chỉ dùng đường dẫn READ-ONLY vì RDS chỉ cho phép scale các instance RO
- Seting autoscaling cho instance và DB hợp lí. Thông thường thời gian để thêm 1 instance RO sẽ mất khá nhiều thời gian, đặc biệt là đối với DB có số lượng record nhiều. Vì vậy phải đảm bảo là số lượng instance được thêm để query data không được phép “quá nhiều” so với số lượng instance của DB. Nếu không khi xử lý quá nhiều tác vụ một lúc, DB có thể bị quá tải, ảnh hưởng đến hệ thống. Thông thường mình để khoảng 3-5 phút sẽ thêm 1 instance targeting, trung bình CPU của DB để scale là 70%.
- Chúng ta luôn có đánh đổi: Nếu ở phần code targeting xử lý nhiều thêm, tối ưu query, logic thêm bao nhiêu, thì ở DB sẽ bớt được đi khối lượng công việc bấy nhiêu.
- Lưu ý quan trọng: Tối đa RDS chỉ cho phép scale out đến 15 RO instance, vì vậy cần set maximum instance cho targeting service ở mức nhất định. Dự án mình đang set là 20 instances.
Gửi thông báo (Push notification)
Đầu tiên chúng ta đến với phần targeting. Phần này không khó về mặt logic. Tuy nhiên chúng ta cần xử lý khéo léo đối với số lượng record trong DB lớn.
Step thực hiện sẽ là:
- Khi có 1 notification đến thời gian targeting, gửi messages vào vào Pushing Queue chứa thông tin S3 key của file đã targeting. Mỗi một notification sẽ có thể có nhiều file, mỗi file ~ 10.000 records.
- Alarm dựa vào metric ApproximateNumberOfMessagesVisible, nếu có message trong queue sẽ trigger scale out để thêm 1 instance mới
- Instance khởi chạy lên, lấy file từ S3 về và thực hiện gửi đến SNS, khi này ApproximateNumberOfMessagesVisible = 0, ApproximateNumberOfMessagesNotVisible = 1
- Khi push hết các record sẽ xóa message trong SQS
- Sau khi xóa message, ApproximateNumberOfMessagesNotVisible (số lượng message đang xử lý) = 0, Alarm sẽ thực hiện trigger scale in.
Lưu ý với bài toán targeting:
- Khi push đến WNS, Firebase,… SNS đã hỗ trợ sẵn. Chúng ta chỉ cần cấu hình SNS sử dụng token của nhà cung cấp để kết nối, phía app sẽ chỉ sử dụng SDK của SNS
- Luôn phải sử dụng VPC Endpoint cho SNS để tăng tốc kết nối, nhanh hơn nhiều lần khi sử dụng đường truyền internet
- Trên mỗi instance, phải sử dụng multithread để tối ưu hiệu năng sử dụng của phần cứng
- SNS trên mỗi region đều có những quotas khác nhau, cần tính toán kĩ số lượng instance tối đa để không bị throttle. Xem quotas ở đây: https://docs.aws.amazon.com/general/latest/gr/sns.html
- Khác với targeting, push này chỉ quan tâm đến số lượng max instance, không quan tâm đến tốc độ scale, nên scale càng nhanh thì end càng sớm. Mình để khoảng 1 phút sẽ thêm 1 instance push
Xử lý lỗi
Thông thường chúng ta sẽ có 2 kiểu lỗi.
- Lỗi từ app -> SNS (Role, connection, Endpoint bị disabled…). Lỗi này thì app khi push sẽ lắng nghe được và có thể xử lý được luôn
- Lỗi từ SNS (Application platform) -> WSN. Trong trường hợp lỗi thứ nhất không xảy ra thì thông thường SNS sẽ trả về status code thành công. Tuy nhiên khi delivery sang nhà cung cấp notification (WNS) cũng có thể gặp 1 vài lỗi khác (Endpoint không tồn tại, Endpoint bị xóa ….), nhà cung cấp sẽ gửi lại thông tin về SNS tuy nhiên việc này lại là bất đồng bộ, không liên quan đến luồng push notification, do vậy app không thể xử lý được.
Đối với bài toán này chúng ta sẽ có luồng xử lý như sau - App sử dụng AWS SNS SDK để gửi thông báo
- SNS(Application platform) xử lý thông tin và gửi sang phía nhà cung cấp notification và trả về thành công cho app
- Sau khi nhà cung cấp notification gửi đến thiết bị không thành công, phản hồi về cho SNS(Application platform). SNS (Application platform) sẽ publish một message đến 1 SNS Topic đã chỉ định trước
- SQS subscribe SNS topic sẽ nhận được message, trigger lambda xử lý data
- Lambda đọc thông tin từ SQS và lưu lại vào DB
Bài toán xử lý lỗi này thường là tùy chọn thêm (optional), không bắt buộc phải có. Tuy nhiên nếu buộc phải yêu cầu xử lý push lỗi thì luôn luôn lưu ý những điểm sau:
- Lỗi từ Notifiication Provider về SNS là bất đồng bộ.
- Lambda function (hoặc EC2, ECS hay bất kì consumer nào) xử lý message từ SQS phải giới hạn số lượng message xử lý đồng thời. Trong trường hợp có quá nhiều message bị lỗi -> số lượng message trong queue quá nhiều, không giới hạn số lượng message xử lý đồng thời có thể gây spam DB write (ảnh hưởng đến toàn bộ hệ thống và các chức năng khác).
Một số vấn đề thường gặp khi targeting
Như đã đề cập ở phần mở đầu, mình sẽ chia sẻ một số vấn đề gặp phải khi push notification
- Đánh index DB sai, query không tối ưu -> Targeting không hiệu quả, có thể gặp lỗi hoặc thiếu data
Với DB có số lượng record lớn, index chuẩn là điều rất quan trọng khi query. Nếu thiếu index, hoặc index sai so với yêu cầu của bài toán thì rất có thể dẫn đến query rất lâu, tốn nhiều tài nguyên DB. Cùng với đó, tối ưu câu query cũng là điều rất cần thiết. Chỉ cần 1 điều kiện không tối ưu có thể kéo hiệu năng của DB giảm đi rất nhiều. Mình từng gặp trường hợp chỉ thêm 1 câu lệnh ORDER BY nhưng làm chết luôn cả 1 hệ thống 
- Xử lý multithread sai
Khi mình xử lý multithread, cần xác định rõ 1 luồng chạy tốn bao nhiều CPU, Memory, đôi khi còn phải quan tâm đến cả network nữa. Từ đó tính toán số lượng thread phù hợp với cấu hình của DB. Nếu tính toán không chuẩn, multi thread có thể làm chậm quá trình push đi nhiều lần. Để cải thiện vấn đề này thì cần có kinh nghiệm về coding, monitoring cũng như load test phải hiệu quả
- Khi push notification chết toàn bộ API
Thực ra bài toán này mình gặp ở 1 App di dộng khá lớn. Mỗi khi push notification đến nhiều người dùng thì hệ thống lại treo khoảng 15-30 phút. Vấn đề không nằm ở việc push notification, vấn đề nằm ở việc hạ tầng phục vụ user chưa đáp ứng đủ.
Ví dụ khi có 1 chương trình ra mắt sản phẩm mới, push notification cho toàn bộ người dùng để giới thiệu. Khi người dùng nhận được thông báo thì vào ứng dụng để xem. Có những người xem xong thì tắt app, có những nhiều xem xong notification thì xem luôn sản phẩm mới, về luôn trang Home để xem thêm thông tin … Như vậy số người dùng thời điểm đó tăng đột biến, có thể gấp 1000 – 2000 lần số người dùng của hệ thống lúc bình thường. Chưa kể mỗi thiết bị có thể call nhiều API khác nhau -> quả tải hệ thống với số lượng user tăng đột biến.
Để giải quyết vấn đề này, chúng ta cần phải scale hệ thống lên trước khi push noitification. Để tiết kiệm chi phí, cần phải tính toán số lượng notification gửi đi, tính toán thêm phần trăm user thường hay click để xem các thông tin khác, buffer lên 1 chút, rồi cài đặt cấu hình phù hợp để đáp ứng số user đó. Hết khoảng thời gian peak time thì scale in.
Kết luận
Bài viết này của mình chỉ đề cập đến 1 bài toán nhỏ của push notification vì có những hệ thống đòi hỏi push notification phức tạp hơn nhiều. Hệ thống triển khai thì mình có tùy chỉnh lại một chút ở cơ chế scaling. Nó đã và đang phục vụ tốt cho ứng dụng của KH. Do một số limit của phía KH nên một số điểm mình nghĩ có thể cải thiện tốt hơn. Chia sẻ đến anh em để mọi người góp ý cũng như nêu ra những điểm cải tiến. Mình thì cũng chỉ viết được những bài chia sẻ về infrastructure, nên một số phần sâu về coding mình cũng không thể viết chi tiết được. Overview thế thôi nhé.
Sai sót chính tả thì comment để mình sửa nhé!
Nguồn: viblo.asia