Mở đầu
Gần đây, các kiến trúc Transformer đã dần dần trở nên phổ biến trong các bài toán về computer vision.
Như đã biết, các kiến trúc Transformer được ứng dụng rất nhiều và đạt hiệu năng rất cao khi sử dụng trong các bài toán NLP, tuy nhiên, đối với các bài toán về computer vision việc sử dụng hiệu quả các kiến trúc Transformer vẫn gặp khó khăn. Một trong những nguyên nhân được cho là gây ra khó khăn trong việc sử dụng Transformer với các bài toán Vision được cho là vấn đề về scale khác nhau giữa các ảnh, vấn đề về “scale khác nhau” có thể hiểu “nôm na” như là trong bức ảnh, các đối tượng (chó, mèo, xe cộ, …) trong ảnh có các kích thước khác nhau hoặc là độ phân giải của ảnh đầu vào rất khác nhau tùy thuộc vào tập data và bài toán, do vậy hiệu năng của mô hình có thể bị ảnh hưởng bởi các kích thước to nhỏ không đồng đều đó. Không giống như bài toán NLP, việc “tách từ” (word token) thường dựa trên khoảng trắng (đối với tiếng Anh) và từ được tách thường đã mang trọn vẹn thông tin của nó, trong bài toán Vision thì việc “tách từ” (word token) từ bức ảnh như thế nào cho hiệu quả để đưa vào mô hình Transformer phức tạp hơn, việc lựa chọn kích thước của “từ” (word hay patch) ở phương pháp Vision Transformer trước thường là dựa trên kích thước cố định (VD: 16×16 pixel) và việc lựa chọn dựa trên kích thước cố định này có vẻ không phù hợp với các bài toán về computer vision. Xuất phát từ tư tưởng trên, vào năm 2021, nhóm tác giả đề xuất một kiến trúc Transformer mới có tên gọi Shifted windows Transformer (Swin Transformer).
Nhìn chung, kiến trúc này có thể coi là bản nâng cấp của Vision Transformer, những điểm mới trong kiến trúc này có thể kể đến như:
- Kiến trúc Transformer phân cấp (hierarchical Transformer), tại các layer sâu, các path hàng xóm gần nhau sẽ dần dần được hợp nhất lại.
- Sử dụng self attention trên 1 vùng cục bộ thay vì toàn bộ ảnh như Vision Transformer, do vậy sẽ tiết kiệm chi phí tính toán hơn.
- Shifted windows, việc sử dụng các “cửa số trượt” sẽ giúp các patch ảnh không bị “bó cứng” khi phải seft attention trong 1 cửa sổ cục bộ mà sẽ có “cơ hội” được gặp và tính self attention cùng với các path khác trong 1 cửa sổ mới.
- Mô hình Transformer output ra nhiều scale khác nhau thay vì chỉ output 1 scale duy nhất như Vision Transformer, đây là một tính chất khá quan trọng của CNN cũng như là một yếu tố để giải quyết các bài toán về computer vision, do vậy backbone Swin Transformer được kỳ vọng sẽ đa dụng hơn cho nhiều bài toán khác nhau, đặc biệt là những bài toán yêu cầu dense prediction như detection, segmentation, …
Phương pháp
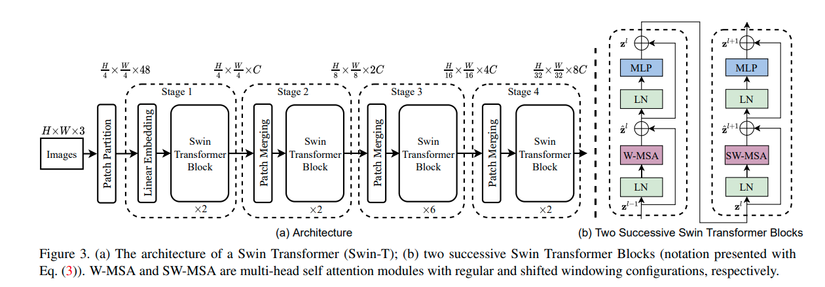
Hình ảnh trên được trích từ trong paper gốc, mô tả kiến trúc tổng quát của Swin-T (Swin Transformer phiên bản tiny) , các phiên bản khác cũng có cơ chế hoạt động như vậy nhưng mô hình sẽ nhiều tham số hơn và yêu cầu khả năng tính toán lớn hơn.
Đầu tiên, ảnh đầu vào là ảnh RGB có kích thước HxWx3, được chia nhỏ làm các patch giống với Vision Transformer, mỗi patch trong ảnh có kích thước 4×4 và được chuyển thành vector có độ dài 4x4x3 = 48 để đưa vào mô hình Swin Transformer.
- Tại Stage 1, lớp Linear Embedding biến không gian vector gốc (48 chiều) thành một không gian vector khác có số chiều là C, sau đó được đưa qua một vài Swin Transformer Block, lúc này số lượng token (hay còn gọi là patch) là H/4 x W/4
- Tại các State 2, 3, 4, mỗi Stage gồm 2 thành phần chính là lớp Patch Merging và một vài Swin Transformer Block.

- Lớp Patch Merging có nhiệm vụ làm giảm số lượng các token bằng cách gộp 4 patch (4 hàng xóm 2×2) thành 1 patch duy nhất (ảnh minh họa trên), như vậy số lượng token khi đi qua Stage 2 sẽ là H/8 x W/8 và độ dài của 1 token là 4C chiều (do gộp 4 path làm 1). Sau đó, các token sẽ được đưa qua 1 lớp Linear để giảm số chiều thành 2C và tiếp tục đưa qua một vài các Swin Transformer Block. Tương tự với các Stage 3 và 4, output của từng Stage lần lượt là H/16 x H/16 x 4C và H/32 x W/32 x 8C.

- Swin Transformer Block: Nhìn chung, đây vẫn là một block Transformer dựa vào cơ chế self attention, tuy nhiên, Swin Transformer Block sử multi-head self attention (MSA) trên 1 vùng cửa số cục bộ thay vì trên toàn bức ảnh như Vision Transformer. Hình ảnh trên mô tả 2 Swin Transformer Block liên tiếp, W-MSA và SW-MSA là multi-head self attention trong Transformer như chúng ta thường biết nhưng với cơ chế “cửa sổ thông thường” và “cửa sổ trượt” tương ứng. Dựa vào hình ảnh, chúng ta có thể thấy cơ chế tính toán của Swin Transformer Block khá tuần tự và dễ hiểu, đầu vào của block sẽ được đưa qua Layer Norm (LN) sau đó đưa qua W-MSA (hoặc SW-MSA) và MLP, xen giữa đó có sử dụng skip connection.

-
Shifted Window based Self-Attention: Việc Vision Transformer sử dụng self attention trên toàn bộ ảnh gây ra vấn đề như đã nói ở phần mở đầu là độ phức tạp của thuật toán sẽ tăng theo số patch. Mà số patch thì phụ thuộc vào kích cỡ ảnh đầu vào, phụ thuộc vào bài toán mà chúng ta cần giải quyết (VD: những bài toán như segmentation yêu cầu dense prediction hoặc yêu cầu phải duy trì high resolution của ảnh thì chúng ta không thể để patch ảnh có kích thước quá lớn dẫn đến việc số lượng patch nhiều và làm tăng chi phí tính toán theo bậc 2 của ảnh đầu vào). Do vậy cơ chế W-MSA và SW-MSA được thiết kế để giải quyết vấn đề đó. Hình minh họa trên mô tả việc tính toán self attention giữa các patch (hình vuông viền xám) trên cùng 1 cửa sổ (hình vuông viền đỏ) với nhau thay vì tính toán self attention giữa các path trên toàn bộ bức ảnh.
-
W-MSA: Giả sử ảnh đầu vào có kích thước HxW, được chia làm các patch và các cửa sổ, mỗi cửa sổ có MxM patch (M được đặt cố định là 7), độ phức tạp tính toán của MSA truyền thống với W-MSA dựa trên cửa sổ là:
-
Ω(MSA)=4HWC2+2(HW)2COmega(MSA) = 4HWC^2 + 2(HW)^2C
-
Ω(WMSA)=4HWC2+2M2HWCOmega(WMSA) = 4HWC^2 + 2M^2HWC
-
-
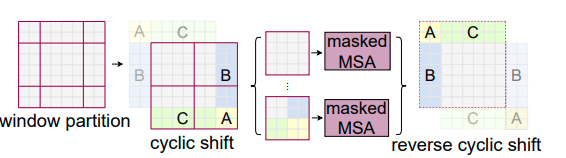
SW-MSA: Nếu chỉ dùng self attention trên 1 cửa sổ có vị trí cố định sẽ làm thiếu đi tính liên kết thông tin với các vùng khác trong ảnh, do vậy có thể ảnh hưởng tới hiệu năng của mô hình. Cơ chế Shifted Windows MSA sẽ dịch cửa sổ đi 1 đoạn và Swin Transformer Block sẽ thực hiện tính toán self attention trên các vị trí cửa sổ mới đó. Sau khi dịch cửa sổ, tại mỗi cửa sổ sẽ có số lượng patch không đồng đều.
-
Efficient batch computation for shifted configuration: Sau khi đã dịch cửa sổ để tính self attention trên các vùng cửa sổ cục bộ mới nảy sinh ra một vấn đề đó là xuất hiện thêm cửa sổ (từ H/M x W/M cửa sổ thành (H/M+1) x (W/M+1) cửa sổ) và có một số cửa sổ có kích thước nhỏ hơn MxM. Theo cách trực quan, phương án để giải quyết vấn đề này là ta sẽ pad thêm để mỗi cửa sổ có đủ kích thước MxM patch và khi tính self attention những thành phần pad thêm vào sẽ bị mask đi. Tuy nhiên, việc padding này sẽ gặp vấn đề về chi phí tính toán khi số lượng cửa sổ là nhỏ, VD khi ta có 4 cửa sổ (2×2), phép dịch cửa sổ sẽ sinh ra 3×3=9 cửa sổ và nếu sử dụng padding và tính toán thì ta phải tính toán self attention trên 9 vùng cửa sổ cục bộ (lớn hơn nhiều so với 4 vùng cửa sổ ban đầu khi chưa dịch). Để giải quyết vấn đề chi phí tính toán, tác giả đưa ra một cách tính “more efficient batch computation approach”, ý tưởng là ảnh sẽ được lặp lại có tính chu kỳ (như hình minh họa bên trên). Ở hình minh họa, hình đầu tiên mô tả cửa khi thực hiện phép dịch xong và ta có thể thấy có tổng cộng 3×3=9 vùng cửa sổ cục bộ để tính self attention, hình kế tiếp mô tả cách tính self attention của tác giả, hiểu “nôm na” là ta vẫn giữ nguyên 2×2=4 cửa sổ và ảnh được “lặp lại có tính chu kỳ” (các vị trí A, B, C trên ảnh được lặp lại), việc tính self attention sẽ được thực hiện trên 4 vùng cửa số giống với lúc chưa dịch và điều này tiết kiệm chi phí tính toán. Cách làm này sẽ làm cho tại một số cửa số chứa những vùng ảnh mà chúng vốn không nằm cạnh nhau trên ảnh gốc, điều này có thể giải quyết bằng cách mask các vùng không cạnh nhau đó lại khi tính self attention.
-
Việc tính toán self attention sẽ sử dụng Relative position bias
-
Attention(Q,K,V)=SoftMax(QKT/d+B)VAttention(Q, K, V) = SoftMax(QK^T/sqrt d + B)V
-
-
Công thức này giống với công thức tính self attention trong Transformer hay Vision Transformer, nhưng có thêm thành phần Relative position bias là
-
B∈RM2×M2B in Reals^{M^2 times M^2}
- Việc thêm thành phần Relative position bias này vào theo như tác giả nói sẽ làm tăng hiệu năng mô hình so với việc sử dụng Absolute position embedding trong Transformer gốc (“We observe significant improvements over counterparts without this bias term or that use absolute position embedding”).
-
Swin Transformer là một backbone đa dụng, có thể kết hợp với nhiều phương pháp khác nhau để giải quyết các bài toán computer vision như classification, detection, segmentation, … và đạt được hiệu năng rất tốt. Bài viết này giới thiệu sơ lược về cách hoạt động của Swin Transformer, các bạn có thể xem chi tiết hơn về các kết quả của Swin Transformer được report trong paper gốc.
Tham khảo
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (https://arxiv.org/pdf/2103.14030.pdf)
- https://sh-tsang.medium.com/review-swin-transformer-3438ea335585
- https://www.facebook.com/1127124110656257/posts/pfbid0SsxZGzDK73xRtdvNa4J5gqN4DWovmCYA8ByVHnwq4kYYM8DSvzhLLUvvnUDdLov2l
Nguồn: viblo.asia