Lời mở đầu
Các mô hình Deep Learning thường có xu hướng đối dữ liệu – data hungry. Đối với các nhiệm vụ cụ thể, nếu như được cung cấp một lượng đầy đủ dữ liệu có những thì các thuật toán supervised learning có thể xử lý rất tốt. Để đạt được hiệu năng cao thì mô hình thường đòi hỏi một lượng khá lớn các dữ liệu có nhãn và chi phí để gán nhãn dữ liệu thường là rất đắt đỏ. Ngược lại, các nguồn dữ liệu không có nhãn trên thực tế lại nhiều vô số kể và chi phí thu thập chúng cũng vô cùng thấp. Đó chính là lý do vì sao các thuật toán giúp tận dụng nguồn dữ liệu không nhãn khổng lồ này là một trong những hướng đi rất tiềm năng trong lĩnh vực AI. Tuy nhiên, các thuật toán unsupervised learning thường là không dễ huấn luyện cũng như khó đạt được hiệu năng cao như các thuật toán supervised learning.
Một câu hỏi dặt ra là:
Liệu chúng ta có thể tạo ra các nhãn một cách free trên các unlabeled data và áp dụng các chiến lược training supervised tương tự trên các dữ liệu này?
Câu trả lời là CÓ THỂ và đó cũng chính là mục tiêu của phương pháp mà chúng ta sẽ bàn tới trong bài viết này – Self supervised learning hay còn gọi là Học tự giám sát. Đây là một phương pháp rất thú vị mà chúng ta có thể tận dụng các chiến lược học giám sát trên dữ liệu và nhãn được tạo tự động từ bản thân các thông tin của dữ liệu. Để có thể hình dung về phương pháp này chúng ta có thể xem hình sau
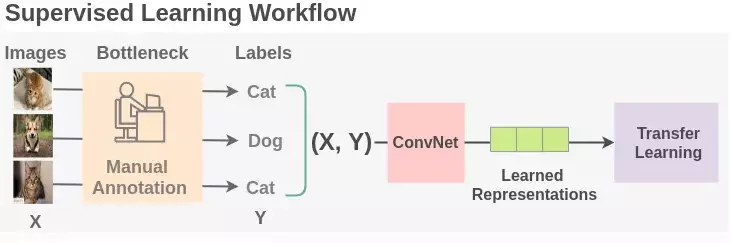
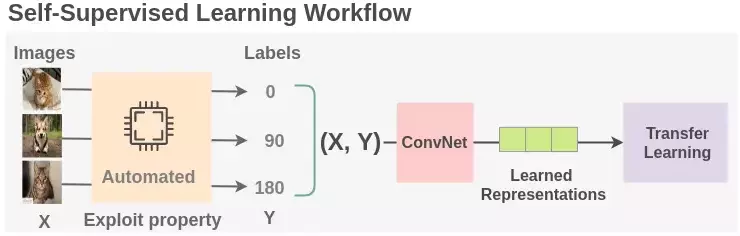
Tư tưởng của học tự giám sát được áp dụng rất thành công trong các language model mà nổi tiếng nhất không thể không nhắc đến BERT. Default task của language model đó là dự đoán next word dựa vào các past sequence. BERT đã làm robust hơn mô hình của mình bằng cách add thêm vào hai auxiliary tasks được huấn luyện trên các self-generated labels.
Trong bài viết này chúng ta sẽ cùng nhau đi tìm hiểu một cách tổng quát nhất về các phương pháp ứng dụng self-supervised learning thành công cho đến thời điểm hiện tại. OK không chần chừ gì nữa, chúng ta sẽ bắt đầu ngay thôi.
Tại sao cần phải áp dụng Self-supervised learning
Self-supervised learning áp dụng với các nhãn được tạo ra hoàn toàn tự động chính vì thế nên số lượng nhãn mà chúng ta định nghĩa ra có thể coi là vô cùng đa dạng tuỳ thuộc vào auxiliary task mà chúng ta định nghĩa. Việc gán nhãn trực tiếp với main task của chúng ta (ví dụ như classification hay segmenattion) thường tốn rất nhiều chi phí về thời gian và tiến bạc. Tuy nhiên việc tạo ra các nhãn tự động cho self supervised learning lại vô cùng đơn giản. Ví dụ chúng ta có thể lấy một bức ảnh, làm mờ nó đi rồi lấy chính bức ảnh ban đầu để làm nhãn cho mô hình khôi phục ảnh chẳng hạn.
Chúng ta cần quan tâm đến self-supervised task hay còn gọi là pretex-task là một nhiệm vụ chúng ta cần phải quan tâm trong quá trình thực hiện self-supervised learning. Bởi lẽ, biểu diễn representation được học từ pretex task này sẽ được sử dụng để transfer learning sang các downstream task của chúng ta nên việc lựa chọn pretex task cho phù hợp là rất quan trọng. Chúng ta sẽ huấn luyện các pretex task này với supervised loss function tuy nhiên chúng ta thường không quan tâm đến final performance của task này. Thứ mà chúng ta quan tâm đó chính là intermediate representation học được với kì vọng rằng representation này có thể mang một thông tin hữu ích giúp bổ trợ cho việc học các downstream task sau này.
Nói một cách tổng quát, tất các các mô hình sinh – generative models đều có thể được coi là một dạng của self-supervised learning nhưng với các mục đích khác nhau. Generative models tập trung vào tính chất đa dạng (diverse) và độ thật (realistic) của dữ liệu được sinh ra. trong khi self supervised learning quan tâm đến việc tạo ra các good features có thể hữu ích cho các downstream tasks.
Phần tiếp theo chúng ta sẽ cùng nhau đi tìm hiểu các phương pháp self-supervised learning áp dụng cho từng loại dữ liệu khác nhau
Một số phương pháp self-supervised learning cho dữ liệu dạng hình ảnh
Dữ liệu dạng hình ảnh là một trong những dạng dữ liệu dê hình dung nhất với chúng ta. Có khá nhiều ý tưởng được đề xuất cho việc áp dụng self-supervised learning trên dữ liệu hình ảnh. Một chiến lược cơ bản đó là huấn luyện một mô hình trên một hoặc một số pretex task với dữ liệu không nhãn sau đó sử dụng các intermediate feature layer của các model này đưa qua một mạng nơ ron ví dụ như một multilayer perceptron để làm một phân loại hình ảnh chẳng hạn. Kết quả cuối cùng của task phân loại sẽ cho biết chất lượng của representation được học bởi pretex task. Chúng ta có thể xem xét một số pretex task cơ bản như sau:
Distortion
Chúng ta kì vọng rằng một chút thay đổi nhỏ về distortion trên image không làm thay đổi original semantic meaning hay các geometric form của nó. Việc giả sử như vậy sẽ giúp cho mô hình học được các đặc trưng bất biến với phép biến đổi distortion. Exemplar-CNN (Dosovitskiy et al., 2015) đề xuất phương pháp khởi tạo tập dữ liệu huấn luyện sử dụng dữ liệu không nhãn. Phương pháp này gồm các điểm chính như sau:
- Các tác giả định nghĩa ra các – Surrogate classes được sinh ra từ tập dữ liệu không nhãn.
- Lấy mẫu ngẫu nhiên các NNseed image patchvới kích thước 32×3232 times 32. Các ảnh này là các ảnh trong dữ liệu không nhãn, có chứa các đối tượng hoặc các bộ phận của một đối tượng Các mẫu này được gọi là “exemplary” patches.
- Mỗi một surrogate class sẽ chứa các image được transformation theo nhiều dạng khác nhau (chúng ta có thể hiểu là một tập hợp rất nhiều các ảnh đã được augmentation từ một seed patch.
- Giả sử chúng ta có 8000 seed patch thì sau khi được transformation sẽ tạo ra 8000 surogate classes
- Pretext task sẽ làm nhiệm vụ phân biệt giữa các surogate classes. Chúng ta hoàn toàn có thể tạo bao nhiêu surogate classes tuỳ thích. Dưới đây là một ví dụ về một surogate classes

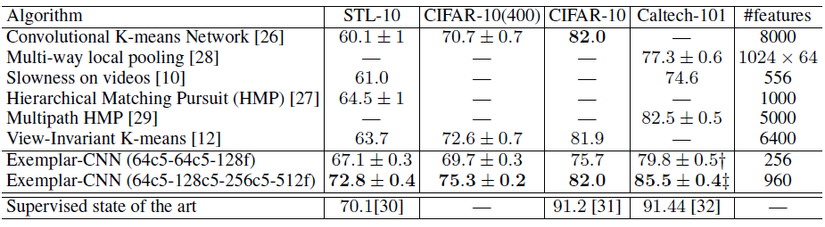
Sau khi huấn luyện pretex task, các feature từ mô hình CNN sẽ được sử dụng để trích chọn đặc trưng và đưa vào mô hình phân loại SVM để phân loại cho downstream task của chúng ta. Kết quả cho thấy sự hiệu quả trên các tập dữ liệu STL-10, thậm chí out perform so với các phương pháp supervised tại thời điểm viết paper.
Rotation
Xoay ảnh và dự đoán phương pháp xoay ảnh là một trong những cách đơn giản được đề xuất trong paper Gidaris et al. 2018. Phương pháp này dựa trên một giả thiết rằng các đặc trưng về mặt ngữ nghĩa của ảnh sẽ invariant với phép xoay ảnh. Mỗi một input image sẽ được xoay bởi các góc khác nhau (bội số của 90∘90^circ tương ứng với các góc xoay [0∘,90∘,180∘,270∘][0^circ, 90^circ, 180^circ, 270^circ]. Model sẽ được huấn luyện để dự đoán phép rotation nào đã được áp dụng lên ảnh. Đây là một bài toán dự đoán 4 class thông thường.
Để có thể học cách phân biệt một image với các different rotations, mô hình sẽ cần phải học được các đặc trưng high-level của các object như đầu, mỏ, mắt … và các vị trí tương đối của chúng chứ không phải là các local partern. Pretex task sẽ giúp cho mô hình có thể học được các semantic concept của objects một cách robust hơn. Chúng ta có thể hình dung rõ hơn trong hình sau:
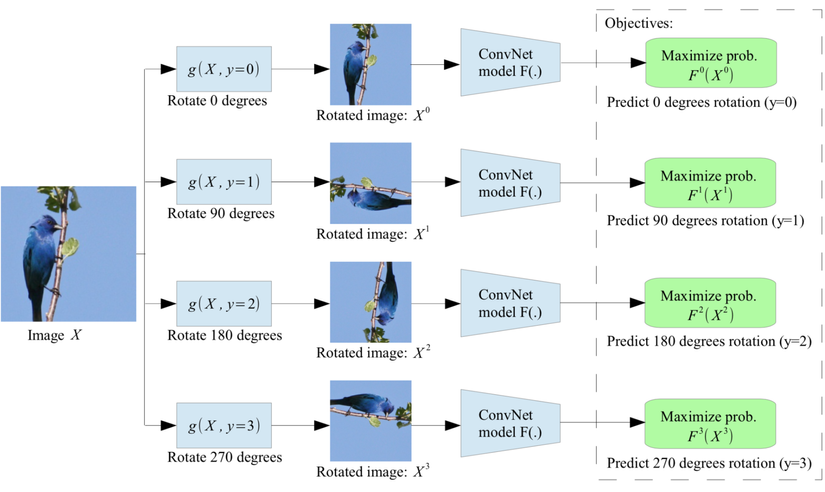
Patches
Một giải pháp khác để thực hiện self supervised learning trên dữ liệu hình ảnh đó chính là extract ra các patché nhỏ của cùng một hình ảnh và bắt mô hình phải predict các mối liên hệ giữa các patches đó. Trong paper Doersch et al. (2015), các tác giả đề xuất huấn luyện pretex task bằng cách cho mô hình dự đoán vị trí tương đối của các patches trong cùng một image. Cụ thể, mỗi một bức ảnh sẽ được chia thành 8 patches nhỏ xung quanh một sampled patch. X đầu vào sẽ là một cặp của patches bao gồm sampled patch và một trong 8 patch nhỏ được lấy theo vị trí trong không gian, đầu ra của mô hình phải dự đoán vị trí tương đối của chúng. Sau khi học được pretext task này thì mô hình sẽ robust với các visual representation

Solving Jigsaw Puzzles
Xuất phát từ ý tưởng Patches đã được trình bày ở trên, có một câu hỏi rằng tại sao chúng ta không sử dụng toàn bộ 9 patches thay vì chỉ sử dụng 2 trong số 9 patches để bắt mô hình phải học một nhiệm vụ khó hơn. Các tác giả trong paper Noroozi & Favaro (2016) đề xuất việc giải một Jigsaw Puzzles giúp cho việc học Visual Representation tốt hơn. Tư tưởng chính của paper này như sau:
- Solving Jigsaw puzzles được xem như một pretext task, nhiệm vụ này không yêu cầu gán nhãn thủ công. Để học được pretex task này thì cả các thông tin feature mapping của các object parts và corect spatial arragement đều phải được mô hình learning.
- Tác giả đề xuất một Context Free Network (CFN) được thiết kế để nhận đầu vào là các patches nhỏ của image và đầu ra là outputs the correct spatial arrangement. Bằng cách này, feature representation học được sẽ robust về đặc trưng context, spatial information và được sử dụng để làm pretraining cho các downstreams task.
Colorization
Colorization là phương pháp được trình bày trong paper (Zhang et al. 2016). Đây là một một pretex task mạnh mẽ trong self supervised learning. Nó là phương pháp để sinh ra các ảnh màu từ một ảnh xám đầu vào. Trong paper gốc có một số điểm cần lưu ý như sau:
- Color space được sử dụng trong paepr là CIELAB color space
- Input đầu vào là lightness channel X (L), và objective của mô hình là học cách mapping lightness channel sang hai channel color tương ứng Y (ab).
- L component thể hiện human perception of lightness trong thang từ 0 đến 100 trong đó 0 tương ứng với giá trị đen và 100 tương ứng với giá trị trắng.
- a component thể hiện green (negative) / magenta (positive) value.
- b component thể hiện blue (negative) /yellow (positive) value.
Về hàm loss, tác giả nhận thấy việc sử dụng cross-entropy loss để dự đoán xác suất rơi vào các binned color value sẽ hoạt động tốt hơn là L2 Loss trên raw values. Để làm được điều đó thì color space ab sẽ được quantized với bucket 10.
Để phân biệt giữa các common color (thông thường là các màu có ab nhỏ của các background như tường nhà, mây…) với các rare colors (thường tương ứng với các key object trong image), hàm loss được sử dụng trong bài báo giúp cân bằng lại trọng số cho các class hiếm gặp
trong đó v(.)v_(.) là các weighting term được sử dụng để tái cân bằng với các class hiếm gặp.
Tư tưởng của phương pháp này cũng giống như việc chúng ta cần tính điểm TF-IDF trong trường hợp của xử lý ngôn ngữ tự nhiên. Nó sẽ giúp chúng ta giảm được độ quan trọng của các common word và tăng độ quan trọng của các special word.
Generative Modeling
Mô hình sinh là một trong những phương pháp rất hữu hiệu đối với những trường hợp chúng ta một học được một robust representation. Pretext task trong generative modeling là việc reconstruct lại original input với cơ chế encoder-decoder từ đó sẽ giúp cho mô hình học được các latent representtation hữu ích. Chúng ta có thể xem xét một số phương pháp
- Denoising autoencoder được trình bày trong paper (Vincent, et al, 2008) học cách reconstruct lại original image với input đã được add thêm noise. Kiến trúc này dựa trên một quan sát trên thực tế rằng con người thường có khả năng nhận ra các object trong một bức ảnh ngay cả khi nó cso noise tức là các main feature cho tác vụ nhận diện hình ảnh có thể extracted và separated từ ảnh đã thêm noise.
- Context Encoderđược trình bày trong paper (Pathak, et al., 2016) được huấn luyện để fill các phần bị thiếu trong ảnh. Gọi M^hat{M} là một binary mask với phần chứa giá trị 0 tương ứng với các pixel sẽ dược bỏ đi trong orignal image và 1 tương ứng với các pixel được giữ lại. Model sẽ được train với sự kết hợp của reconstruction (L2) loss và the adversarial loss. Các vùng bị xoá đi có thể có bất kì hình dạng nào. Công thức loss function của nó được biểu diễn như sau
L(x)=Lrecon(x)+Ladv(x)Lrecon(x)=∥(1−M^)⊙(x−E(M^⊙x))∥22Ladv(x)=maxDEx[logD(x)+log(1−D(E(M^⊙x)))]begin{aligned}
mathcal{L}(mathbf{x}) &= mathcal{L}_text{recon}(mathbf{x}) + mathcal{L}_text{adv}(mathbf{x})\
mathcal{L}_text{recon}(mathbf{x}) &= |(1 – hat{M}) odot (mathbf{x} – E(hat{M} odot mathbf{x})) |_2^2 \
mathcal{L}_text{adv}(mathbf{x}) &= max_D mathbb{E}_{mathbf{x}} [log D(mathbf{x}) + log(1 – D(E(hat{M} odot mathbf{x})))]
end{aligned}
Trong đó E(.)E(.) là encoder và D(.)D(.) là decoder
Khi chúng ta nhân ảnh đầu vào với mask nhị phân nói trên, context encoder sẽ loại bỏ hoàn toàn các thông tin trên tất cả kênh màu của ảnh đầu vào tại vị trí mask = 0. Điều này đôi khi khiến cho lượng thông tin bị mất mát là quá lớn. Một câu hỏi đặt ra đó là, làm thế nào để chỉ ẩn đi thông tin của một vài channel nhất định (subset) chứ không phải tất cả các channel. (Zhang et al., 2017) đề xuất một phương pháp gọi là Split-Brain Autoencoders. Tư tưởng chính của nó như sau:
- Mỗi một raw image sẽ được chia thành 2 subset channel riêng biệt trong color space.
- Một mạng nơ ron được split thành hai sub-network và được huấn luyện để thực hiện một nhiệm vụ khó đó là từ một subset channel, dự đoán ra subset còn lại. Đây được gọi là cross-channel prediction task và biểu diễn học được không cần sử dụng đến dữ liệu có nhãn.
Cụ thể hơn, thuật toán này sẽ hoạt động như sau:
- Mỗi input data XX sẽ được chia thành X1X_1 and X2X_2
- Sau đó X1X_1 sẽ được đưa qua F1F_1 để predict X2X_2
- Tương tự X2X_2 sẽ được đưa qua F2F_2 để predict X1X_1
- Hàm loss L2 hoặc CE (trong trường hợp giá trị đầu ra của color channel được quantized) được sử dụng để tối ưu mô hình.
Kết luận
SElf-supervised learning là một trong những phương pháp hữu ích để chúng ta học được các biểu diễn tốt cho tập dữ liệu từ bản thân các nguồn dữ liệu không nhãn. Việc học này giúp cho mô hình sẽ robust hơn trên các downstream task cụ thể. Nội dung trong bài viết này khá tổng quan và trong các bài tiếp theo mình sẽ viết rõ hơn về Generative models và Constrastive Representation Learning. Hẹn gặp lại các bạn trong các bài viết tiếp theo
Nguồn: viblo.asia