Giới thiệu về Rasa
Rasa là framework mã nguồn mở được phát triển bởi RASA Inc vào năm 2017, Rasa giúp cho việc phát triển các chatbot máy học một cách thuận tiện hơn, có thể giúp cho những người chưa biết gì về NLP vẫn có thể xây dựng cho mình một chatbot thông minh. Cơ bản về RASA các bạn có thể tìm hiểu trên docs của Rasa hoặc thông qua chuỗi bài viết Xây dựng chatbot Messenger cập nhật thời khóa biểu cho sinh viên của anh Bui Tien Tung – chuỗi bài viết được viết viết trên Rasa 2.0, giờ là phiên bản 3.0 nên có đã có một số thay đổi, mình sẽ viết trong một bài viết khác, Tạm thời các bạn có thể tham khảo chuỗi bài viết trên
BERT là gì?
Nói ngắn gọn, BERT là một State-of-art hay là một bước đột phá mới trong công nghệ xử lý ngôn ngữ tự nhiên vào thời điểm nó ra mắt[1]. Để tích hợp BERT vào bên trong NLU Rasa cũng không phải là khó, trong bài viết này, chúng ta hãy cùng thử cài đặt so sánh 3 thuật toán là Bag-Of-Words, BERT và RoBERTa và so sánh sự hiệu quả của chúng.
Tích hợp BERT vào Rasa
Khởi tạo dự án
Chúng ta sẽ bắt đầu với một chương trình mẫu của Rasa, chương trình mẫu này sẽ cung cấp cho ta một số intent và kịch bản mẫu, bạn cũng có thể tích hợp vào dự án hiện tại của bạn nhé. Đầu tiên là clone về từ Github của dự án:
git clone [email protected]:RasaHQ/rasa-demo.git
Sau khi clone xong, bạn sẽ cần cài đặt các thư viện cần thiết thông qua pip:
pip install -r requirements.txt
pip install "rasa[transformers]"
Bây giờ hãy tạo một thư mục mới để chứa các cấu hình:
mkdir config
Tạo các cấu hình pipeline
Nội dung file config/config-light.yml sử dụng CountVectorsFeaturizer:
recipe: default.v1
language: en
pipeline:
- name: WhitespaceTokenizer
- name: CountVectorsFeaturizer
- name: CountVectorsFeaturizer
analyzer: char_wb
min_ngram: 1
max_ngram: 4
- name: DIETClassifier
epochs: 200
policies:
Nội dung file config/config-bert.yml:
recipe: default.v1
language: en
pipeline:
- name: WhitespaceTokenizer
- name: LanguageModelFeaturizer
model_name: bert
model_weights: bert-base-uncased
- name: DIETClassifier
epochs: 200
- name: EntitySynonymMapper
policies:
Nội dung file config/config-roberta.yml:
recipe: default.v1
language: en
pipeline:
- name: WhitespaceTokenizer
- name: LanguageModelFeaturizer
model_name: roberta
- name: DIETClassifier
epochs: 200
- name: EntitySynonymMapper
policies:
Trong tất cả trường hợp, chúng ta đều dùng DIETClassifier để nhận dạng intent và entity với 200 epochs, tuy nhiên ở mỗi cấu hình có một chút khác biệt.
Trong cấu hình light, chúng ta dùng CountVectorsFeaturizer, nó sẽ tạo một túi từ (bag-of-word) để đại diện cho mỗi từ. Còn đối với bert và roberta, chúng ta sẽ dùng LanguageModelFeaturizer, featurerizer này sẽ cho phép sử dụng các pre-trained model, mà ở đây sẽ là BERT và RoBERTa.
Kiểm tra độ hiệu quả:
Đầu tiên cần tạo thư mục chứa kết quả trước đã:
mkdir gridresults
Tất cả các thông tin sẽ được lưu vào thư mục gridresults này. Bắt đầu chạy thôi:
rasa test nlu --config configs/config-light.yml
--cross-validation --runs 1 --folds 2
--out gridresults/config-light
rasa test nlu --config configs/config-bert.yml
--cross-validation --runs 1 --folds 2
--out gridresults/config-bert
rasa test nlu --config configs/config-roberta.yml
--cross-validation --runs 1 --folds 2
--out gridresults/config-roberta
# output from the light model
2020-03-30 16:21:54 INFO rasa.nlu.model - Starting to train component DIETClassifier
Epochs: 100%|███████████████████████████████| 200/200 [17:06<00:00, ...]
2020-03-30 16:23:53 INFO rasa.nlu.test - Running model for predictions:
100%|███████████████████████████████████████| 2396/2396 [01:23<00:00, 28.65it/s]
...
# output from the bert model
2020-03-30 16:47:04 INFO rasa.nlu.model - Starting to train component DIETClassifier
Epochs: 100%|███████████████████████████████| 200/200 [17:24<00:00, ...]
2020-03-30 16:49:52 INFO rasa.nlu.test - Running model for predictions:
100%|███████████████████████████████████████| 2396/2396 [07:20<00:00, 5.69it/s]
# output from the roberta model
2020-03-30 17:47:04 INFO rasa.nlu.model - Starting to train component DIETClassifier
Epochs: 100%|███████████████████████████████| 200/200 [17:14<00:00, ...]
2020-03-30 17:49:52 INFO rasa.nlu.test - Running model for predictions:
100%|███████████████████████████████████████| 2396/2396 [01:59<00:00, 19.99it/s]
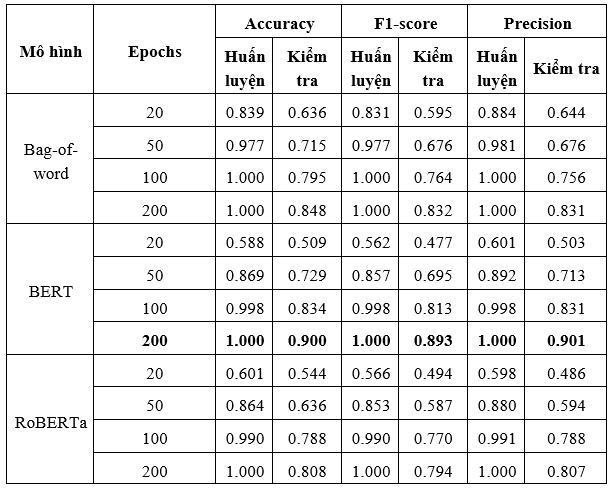
Kết quả:
References:
https://viblo.asia/p/bert-buoc-dot-pha-moi-trong-cong-nghe-xu-ly-ngon-ngu-tu-nhien-cua-google-RnB5pGV7lPG
Nguồn: viblo.asia