I. Lời mở đầu
Xin chào mọi người, mình là Mạnh đây. Chắc mọi người đã quen thuộc với những lớp mạng CNN (Convolution neural networks) được sử dụng rất nhiều trong các mô hình học sâu rồi nhỉ. Hôm nay mình xin giới thiệu một người anh em của CNN – Deformable Convolution Networks (DCN). Người anh em này so với ông CNN có khả năng mô hình hóa chuyển đổi (transformation modeling capability) tốt hơn rất nhiều phù hợp trong các bài toán như . Nào chúng ta cùng đi phân tích paper Deformable Convolutional Networks để cùng tìm hiểu thêm nhé.
II. Nội dung
1. Giới hạn của mạng tích chập (CNN)
Mạng tích chập hay Convolutional neural networks đã và đang đạt được nhiều thành tựu trong cách bài toán nhận dạng như image classification, sematic segmentation, object detection. Tuy nhiên CNN vẫn còn một số nhược điểm như:
- Thiếu cơ chế học biến đổi hình học: Khả năng học biến đổi hình học của các vật thể như xoay ngang, xoay dọc, phóng to, thu nhỏ, nhiễu,… đều đến từ việc tạo ra lượng dữ liệu khổng lồ qua các phương pháp như augmentation. Phương pháp này có hạn chế đó là biến đổi như nào chúng ta cần phải biết trước hoặc giả định sẽ có biến đổi như thế nên dữ liệu biến đổi như thế nào sẽ bị giới hạn nhiều. Do đó mô hình cũng sẽ kém chính xác khi gặp những biến đổi chưa xác định
- Vẫn có một số simple hand-crafted modules: là các module có cách thức hoạt động đơn giản như max-pooling, …. mục đích là để nhận dạng đối tượng dưới các biến đổi nhỏ (small translation invariance). Ví dụ như nhận dạng con mèo trắng hoặc đen.
2. Giải pháp Deformable Convolutional Networks
Trong paper này, nhắm giải quyết các vấn đề của mạng CNN, nhóm tác giả đã đề xuất Deformable Convolution Networks bao gồm hai modules
- Deformable Convolution
- Deformable RoI pooling
2.1. Deformable Convolution
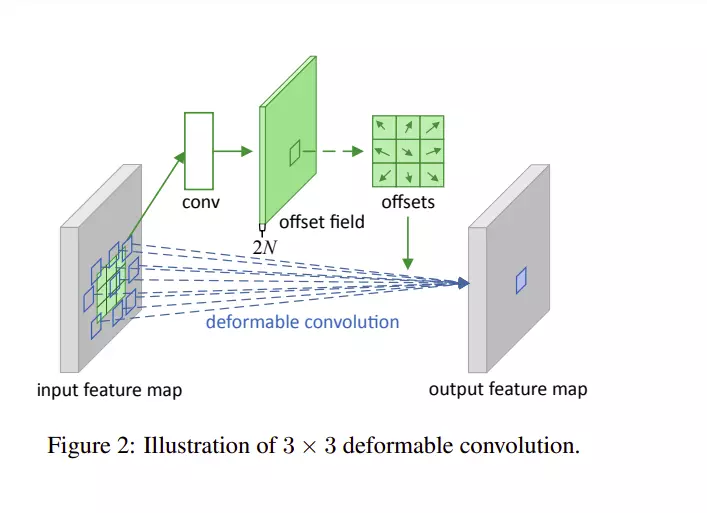
Deformable Convolution xuất phát ý tưởng cộng thêm vào các vị trí lấy mẫu trong các lớp convolution truyền thống một mảng offsets 2 chiều. Điều này cho phép lớp tích chập lấy mẫu tại những vị trí đa dạng hơn. Đặc biệt các giá trị offsets này điều được học từ các
bản đồ đặc trưng trước đó thông qua các lớp tích chập nhờ vậy các giá trị offsets linh hoạt thích ứng với dữ liệu đầu vào
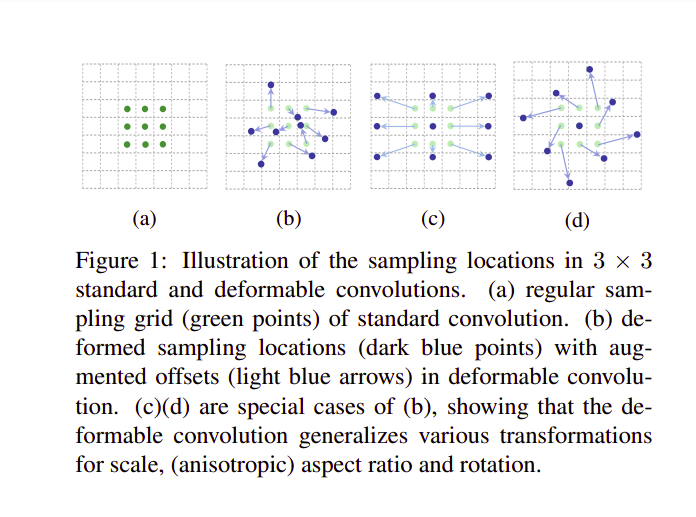
Trước khi đi vào công thức tính của Deformable Convolution, ta cũng nhắc lại công thức của Convolution truyền thống. Convolution truyền thống thường thực hiện theo 2 bước:
- Lấy mẫu bằng cách sử kernel hay lưới R trượt qua bản đồ đặc trưng đầu vào.
- Tổng hợp các giá trị lấy mẫu có đánh trọng số bởi w (weight)
Với mỗi vị trí p0p_0 trên bản đồ đặc trưng đầu ra y, ta có:
y(p0)=∑pn∈Rw(pn)∗x(p0+pn)y(p_0) =sum_{p_n ∈ R} w(p_n) * x(p_0 + p_n)
Trong đó pnp_n thống kê toàn bộ các vị trí trong lưới R.
Vẫn mang âm hưởng của convolution truyền thống, lưới lấy mẫu R của deformable convolution được biến đổi với offsets ∆pn∆p_n, ta sẽ có công thức như sau:
y(p0)=∑pn∈Rw(pn)∗x(p0+pN+∆pn)y(p_0) = sum_{p_n ∈ R} w({p_n}) * x(p_0 + p_N + ∆p_n)
2.2. Deformable RoI pooling
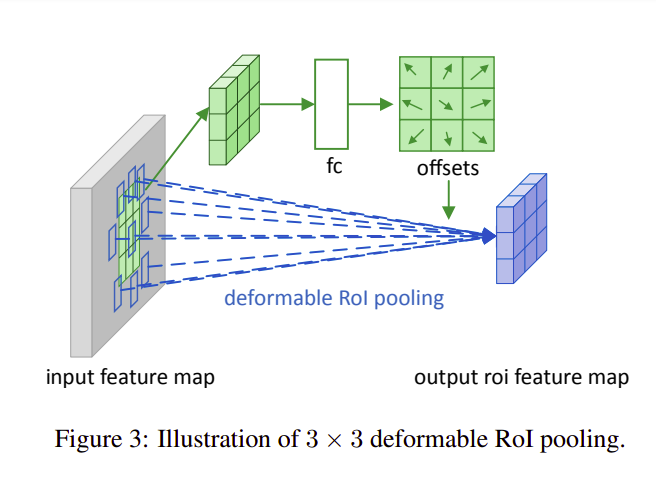
RoI pooling rất hay được sử dụng trong gợi ý các vùng chứa đối tượng trong các bài toán object detection. Lớp pooling này giúp chuyển một vùng đầu vào có kích thước bất kì thành vùng đặc trưng có kích thước cố định.
Cách thức hoạt động của lớp này diễn ra như sau:
Bước 1 RoI pooling chia RoI hay vùng đầu vào thành k x k ô và bản đồ đặc trưng đầu ra y có kích thước k x k
Bước 2 Với mỗi ô có vị trí tọa độ (i, j) ở RoI đầu vào, ô vị trí (i, j) ở feature map đầu ra sẽ được tính:
y(i,j)=∑p∈bin(i,j)x(p0+p)/nij(1)y(i, j) = sum_{p ∈ bin(i, j)} x(p_0 + p) / n_{ij} (1)
Đối với Deformable RoI pooling, công thức sẽ được tính khác một chút giống như Deformable Convolution vậy.
y(i,j)=∑p∈bin(i,j)x(p0+p+∆pij)/nijy(i, j) = sum_{p ∈ bin(i, j)} x(p_0 + p + ∆p_{ij}) / n_{ij}
Ở đây ∆pij∆p_{ij} được tính như sau: một lớp fully connect nhận đầu vào là pooled feature map tính ra ∆pij′∆p’_{ij}. Sau đó ∆pij=γ∗∆pij′∗(w,h)∆p_{ij} = gamma * ∆p’_{ij} * (w, h)
2.3. Position-Sensitive (PS) RoI pooling
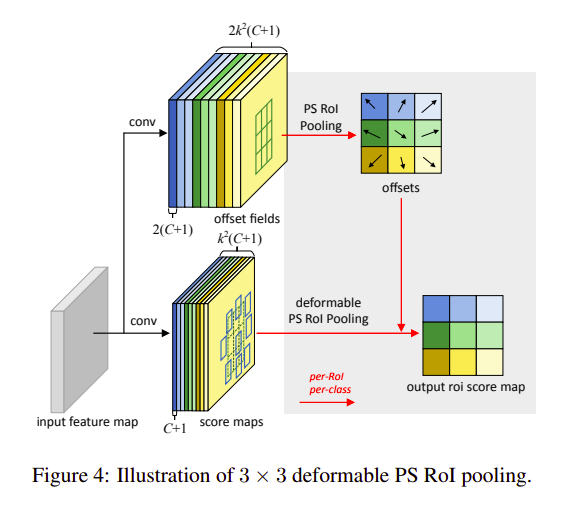
Tương tự như Deformable RoI pooling, PS RoI pooling cũng chia vùng RoI thành k x k ô. Với vùng RoI đầu vào có kích thước w x h, mỗi ô sẽ có kích thước wk∗hkfrac{w}{k} * frac{h}{k}
PS RoI pooling có hai điểm khác biệt so với Deformable RoI Pooling:
Cách tính offset: một lớp convolution từ feature map đầu vào tạo ra offsetfield có channel là 2k2(C+1)2k^2(C + 1) tương ứng với k2k^2 ô, C + 1 class, 2(C + 1) do offset là mảng 2 chiều. Hay là một class ta có k2k^2 feature map. k2k^2 feature map nà biểu diễn tọa độ 2 chiều của top-left, top-center, bottom right,…. của đối tượng.
Tạo score map: Thay vì thực hiện pooling trực tiếp trên feature map đầu vào. PS RoI pooling tạo score map có channel k2(C+1)k^2(C + 1) tương ứng mỗi class có k2k^2 feature map.
3. Một số phương pháp cùng chủ đề
Ngoài deformable convolution networks, cũng đã có một số phương pháp được nghiên cứu để khắc phục nhược điểm của CNN
3.1 Spatial Transform Networks (STN)
STN lấy ý tưởng từ phương pháp affine transform tuy nhiên các tham số chuyển đổi không gian được học từ chính dữ liệu huấn luyện. STN kết hợp mạng backbone chính qua đó tối ưu thông qua hàm loss của nhiệm vụ thực hiện như image classification, object detection,… Tuy nhiên việc học được các tham số chuyển đổi rất khó do đó STN mới chỉ đạt thành tựu trong một số bài toán đơn giản.
3.2 Active Convolution
Activate convolution thực hiện augment các vị trí lấy mẫu với offset được học từ dữ liệu. Nghe qua đoạn này có vẻ khá giống deformable convolution tuy nhiên Active Convolution chia sẻ offset trên cả các vị trí khác nhau trong khi đó nhờ việc chia thành các ô deformable convolution chỉ có chung offset trên những vùng cố định.
Ngoài ra còn rất nhiều các phương pháp khác mà các bạn có thể tham khảo trong paper như Atrous Convolution, Dynamic Filter, ….
III. Lời kết
Để các mô hình học sâu xử lý được cả những dữ liệu nhiễu chưa gặp bao giờ luôn là vấn đề thách thức không nhỏ. Và deformable convolution networks là một trong những mạng hiệu quả, chi phí thấp cùng với khả năng tích hợp dễ dàng vào các mạng có sẵn để hạn chế một phần vấn đề này. Cảm ơn các bạn đã theo dõi bài viết của mình. Hẹn gặp lại trong bài viết sấp tới.
Tài liệu tham khảo
Nguồn: viblo.asia