Giới thiệu
Nếu như chỉ được xây dựng một cách thông thường và không có ý định ngay từ ban đầu thì các mô hình Deep Learning tồn tại rất nhiều lỗ hổng về bảo mật. Một số cách tấn công mô hình rất phổ biến đó là tạo nên advesarial example bằng các thêm “noise” hay sử dụng các véc tơ để bóp méo ảnh đầu vào khiến cho ảnh tuy không có gì thay đổi với nhận thức của con người nhưng có thể khiến cho máy nhận định sai nhãn. Thực tế cho thấy, bảo mật của các mô hình Deep Learning nhạy cảm đến nỗi việc thay đổi ngay cả 1 điểm của ảnh (1 pixel) cũng có thể khiến cho mô hình phán đoán sai. Bài viết dưới đây sẽ làm rõ hơn cách tấn công chỉ thay đổi 1 pixel này. Bài viết sẽ giả sử các bạn đã nắm được kiến thức sơ lược về Adversarial Robustness, nếu chưa thì hãy tìm hiểu thêm về mảng này qua các bài viết Tấn công và phòng thủ bậc nhất và Spatial Transformation
Mô tả bài toán
Để tìm được adversarial examples cho các mô hình Deep Learning, bài toán chúng ta phải giải quyết là dạng bài toán tối ưu hóa với điều kiện ràng buộc. Giả sử rằng chúng ta có một mô hình phân loại, biểu diễn dưới dạng hàm số ff, ảnh đầu vào của mô hình là xx (xx có n dimension và nhãn đúng của xx là t). Vậy xác suất phân loại đúng nhãn của ảnh đầu vào x là ft(x)f_{substack{t}}(x). Đồng thời ta có véc tơ e(x)=(e1,….,en)e(x) = (e_{substack{1}}, …., e_{substack{n}}), là lượng noise thêm vào ảnh để tạo nên adversarial examples. Véc tơ được tạo nên dựa trên xx, class muốn nhắm tới (nếu như là tấn công có chủ đích – target attack) và L là giới hạn thay đổi của ảnh để đảm bảo rằng đa phần của ảnh vẫn được giữ nguyên để mắt thường không nhận ra được sự thay đổi nào rõ rệt, L thường sẽ được đo bằng chiều dài của véc tơ e(x)e(x). Vậy bài toán tối ưu hóa được đưa ra là:
maxe(x)∗fadv(x+e(x))max_{substack{e(x)*}} quad f_{substack{adv}}(x+e(x))
subject to∥e(x)∥≤Lsubject thinspace to quad text{textbardbl} e(x) text{textbardbl} leq L
Bài toán này liên quan đến 2 vấn đề đưuọc giải quyết đó là tìm được dimension cần để thêm noise và độ thay đổi tương ứng đến từng dimension. Đó là bài toán chung cho việc tìm adversarial examples, với bài toán one-pixel, phương trình tối ưu hóa sẽ được thay đổi 1 chút về điều kiện:
maxe(x)∗fadv(x+e(x))max_{substack{e(x)*}} quad f_{substack{adv}}(x+e(x))
subject to∥e(x)∥≤dsubject thinspace to quad text{textbardbl} e(x) text{textbardbl} leq d
Trong đó, dd là một số nhỏ nói chung, còn trong phương pháp tấn công 1-pixel đang được nói đến, dd sẽ được lấy giá trị là 1. Phương pháp tấn công one-pixel có thể được nhìn nhận như việc làm nhiễu loạn điểm dữ liệu theo hướng song song với hướng của trục của một trong các dimensions. Khái quát phương pháp này lên, chúng ta có thể áp dụng n cho n-pixel với n là số nhỏ, lấy ví dụ, sau khi khái quát chúng ta có thể có phương pháp tấn công 5-pixel tạo nên sự nhiễu loạn theo 5 hướng của 5 trong n dimensions. Phương pháp này hoàn toàn ngược lại với phương pháp tạo adversarial examples mà chúng ta thường biết đến. Phương pháp thông thường sẽ làm nhiễu loạn dữ liệu trên tất cả các pixels với một điều kiện ràng buộc về giới hạn của sự thay đổi, tuy nhiên với phương pháp few-pixel attack hay cụ thể là one_pixel attack, sự thay đổi của ảnh đầu vào sẽ chỉ tập trung trên một hoặc một vào điểm ảnh nhưng sự thay đổi là không giới hạn
Differential Evolution (DE)
DE là một thuật toán tối ưu khá có tiếng thường được sử dụng để giải quyết những bài toán multimodal phức tạp. DE là một nhánh của thuật toán tiến hóa – evolutionary algorithms nhưng nó vượt trội hơn bởi cơ chế trong khâu chọn lọc population giúp cho DE giữ được sự đa dạng và điều này khiến cho khi áp dụng vào thực tế, kết quả từ thuật toaasn này được kì vọng là hiệu quả hơn so với các thuật toán dựa trên gradient hay thậm chí cả những thuật toán khác thuộc về EA.
Tóm tắt một cách đơn giản cách thức hoạt động của thuật toán này: Trong mỗi một vòng lặp, một tập hợp các giá trị thử sẽ được tính toán từ giá trị mục tiêu hiện tại, sau đó sẽ so sánh các gí trị thử với gí trị mục tiêu. Nếu giá trị thử có trị số phù hợp lớn hơn thì sẽ trở thành giá trị mục tiêu trong vòng lặp tiếp theo.
Vì thuật toán này không sử cần sử dụng tới gradient vì vậy không có yêu cầu rằng hàm số tính toán của chúng ta phỉa khả vi. Bởi thế nên phương pháp này được tin rằng có ứng dụng rộng rãi hơn phương pháp truyền thống sử dụng gradient. Trong tạo nên adversarial examples, DE cũng có một số những lợi thế nhất định như xác suất cao hơn để tìm được global optima, yêu cầu ít hơn (không đòi hỏi phương trình phải khả vi – như đã nói ở trên) và đơn giản
Phương pháp
Chúng ta sẽ mã hóa những sự nhiễu loạn vào trong một array (giá trị thử) đã được tối ưu bởi phương pháp DE nói trên. Một giá trị thử sẽ chứa một số lượng pertubation nhất định và mỗi perturbation là một tuple bao gồm 5 giá trị, 2 giá trị x, y giúp xác định tọa độ và 3 giá trị màu sắc RGB của perturbation. Mỗi một perturbation sẽ thay đổi 1 pixel.
Theo công thức DE thông thường được viết dưới đây, số lượng giá trị thử ban đầu sẽ là 400 và sau mỗi một vòng lặp, 400 giá trị thử mới sẽ được tạo ra.
xi(g+1)=xr1(g)+F(xr2(g)−xr3(g)),x_{substack{i}}(g+1) = x_{substack{r1}}(g) + F(x_{substack{r2}}(g) – x_{substack{r3}}(g)),
r1≠r2≠r3r1 not = r2 not = r3
Trong đó:
- xix_{substack{i}} là một element của giá trị thử
- r1,r2vaˋr3r1, r2 và r3 là các số ngẫu nhiên
- FF là tham số tỉ lệ được đặt là 0.5
- gg là số chỉ hiện tại của của bước tạo ra các giá trị thử
Một khi được tạo ra, các giá trị thử sẽ được so sánh với giá trị ban đầu tương ứng tạo ra nó, giá trị tốt hơn sẽ được giữ lại cho vòng lặp sau
Kết quả
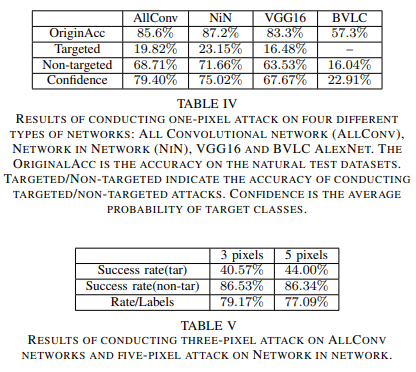
Trên đây là một số kết quả được lấy từ One Pixel Attack for Fooling Deep Neural Networks.
Nhận xét
Cá nhân mình thấy từ kết quả của paper, phương pháp tấn công này đem lại hiệu quả chưa cao nhưng vẫn còn có thể cải thiện bằng các cách khác nhau như sử dụng một phương pháp tối ưu hóa tốt hơn DE, v..v.. Tuy rằng phương pháp này chưa đem lại hiệu quả cao nhưng đã cho thấy một phương pháp tấn công mới có thể khái quát để áp dụng cho nhiều các mô hình khác nhau. Đồng thời, chứng minh được một điều rằng các mô hình hiện nay rất nhạy cảm ngay cả với những sự nhiễu loạn nhỏ.
Nguồn: viblo.asia